The IncidentHub Blog
Notes on vendor reliability, outages, and status monitoring from the IncidentHub team.

The 2024 List of Incident Management Resources

How to Configure a Remote Data Store for Prometheus

A Beginner's Guide To Service Discovery in Prometheus

The No-Nonsense Guide to Runbook Best Practices

The Ultimate List of Incident Management Tools in 2024

The Rising Role of Slack in Incident Management

The 2024 Guide to Open Source Status Page Providers

Best Practices for Choosing a Status Page Provider
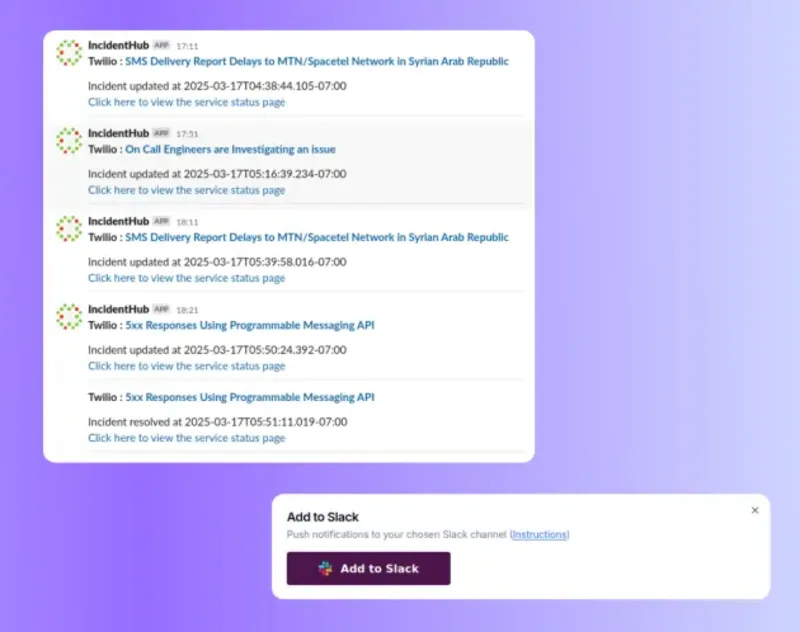
Integrate Incident Alerts Into Your Slack Workspace
A Guide to Monitoring Multiple Status Pages

Integrate Incident Alerts With Discord Using Webhooks
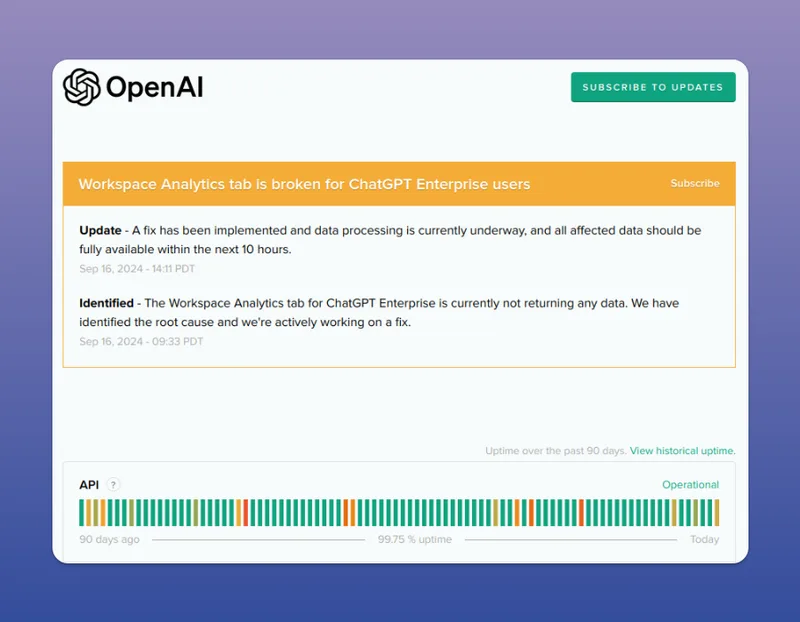
A Step by Step Guide to Checking if a SaaS is Down

When Alerts Don't Mean Downtime - Preventing SRE Fatigue
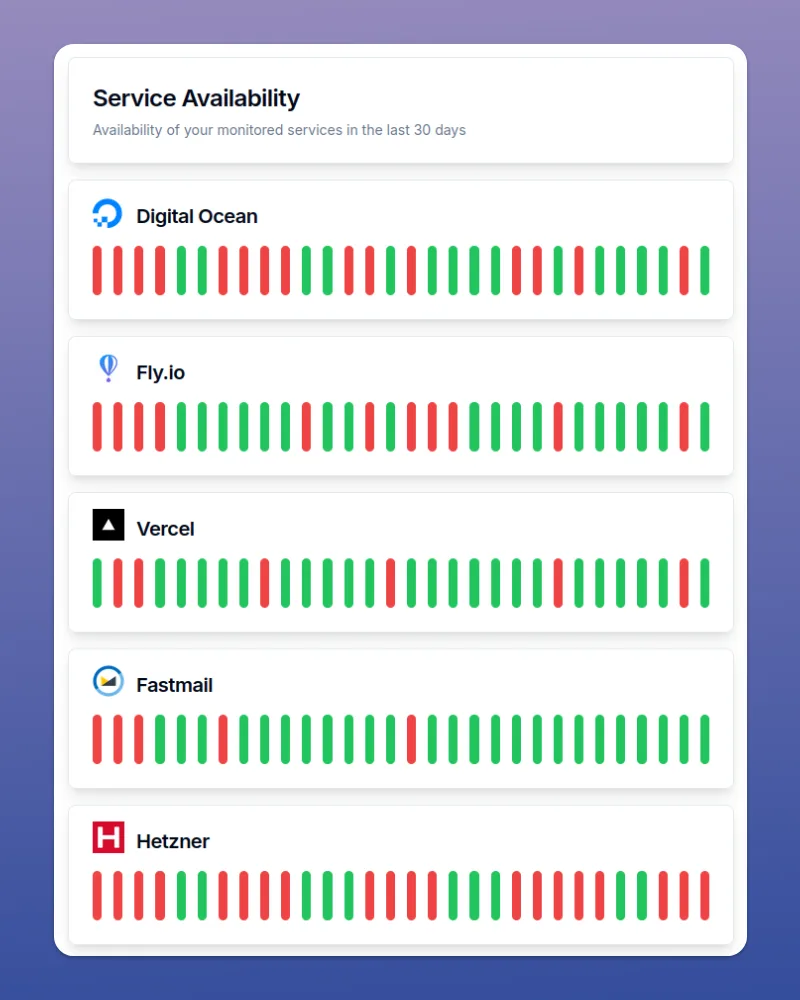
Incident Archaeology – Dig Into Your Services' Past With IncidentHub's Availability Page
