The IncidentHub Blog
Notes on vendor reliability, outages, and status monitoring from the IncidentHub team.

Product Update - July 2026

The July 24, 2026 AWS us-west-2 Outage: Network Routing and a Long Recovery Tail

The July 23 2026 Azure West US Outage: IP Route Removal and Downstream Impact

H1 2026 Cloud and SaaS Reliability Report

The July 2026 AWS CloudFront Outage: VPC Origins, Cascade Impact, and What Broke
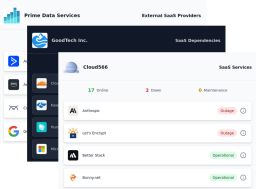
Vendor Outage Monitoring for MSPs: Per-Client Status Pages and Custom Dashboards

Product Update - June 2026

Product Update - May 2026

GitHub Outages 2025 - 2026: Reliability Analysis and Outage History

Why IncidentHub's Alerting is Better than Other Status Page Aggregators'

Product Update - March 2026

The Definitive AWS Outage Report 2025: Reliability Analytics and Cascade Impact
How to Monitor SaaS Status in 2026 : A Complete Guide

Major Cloud Outages of 2025
