How to Monitor SaaS Status in 2026 : A Complete Guide

Introduction
This is an updated and expanded version of the older guide.
According to the 2025 State of SaaS report, organizations use an average of 106 SaaS apps.
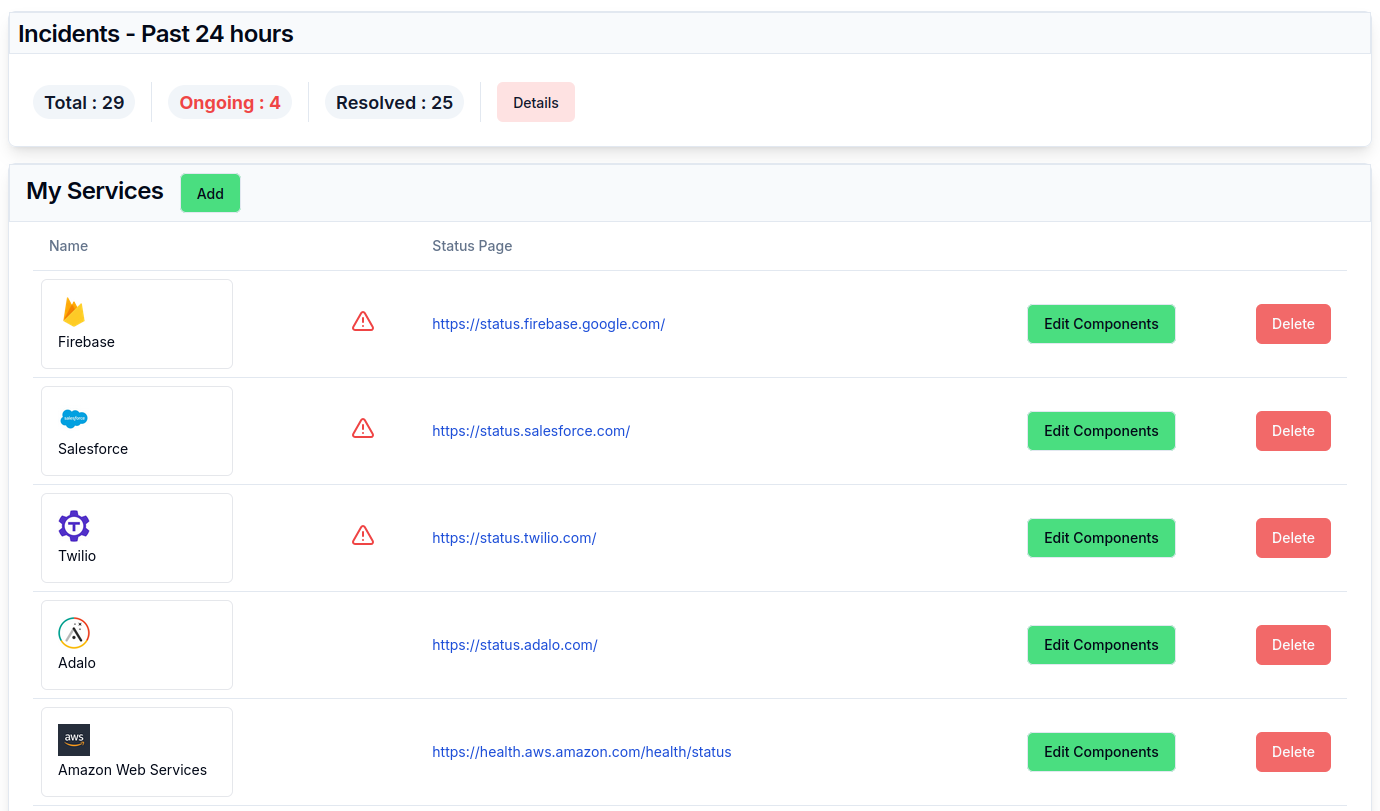
Staying on top of your SaaS vendors' status is as important as monitoring your own services. The Cloudflare, AWS, Azure, and Google Cloud outages in 2025 were strong reminders of this fact. As a result of these outages, many SaaS services that depend on them experienced outages as well, leading to a cascading effect which took down hundreds of vendors and affected thousands of users. Cloud and SaaS outages are not isolated any longer but usually happen in groups due to the dependency chain.
This article aims to be a comprehensive guide on how to monitor the uptime status of your SaaS and Cloud vendors.