When Alerts Don't Mean Downtime - Preventing SRE Fatigue
· 3 min read

Introduction
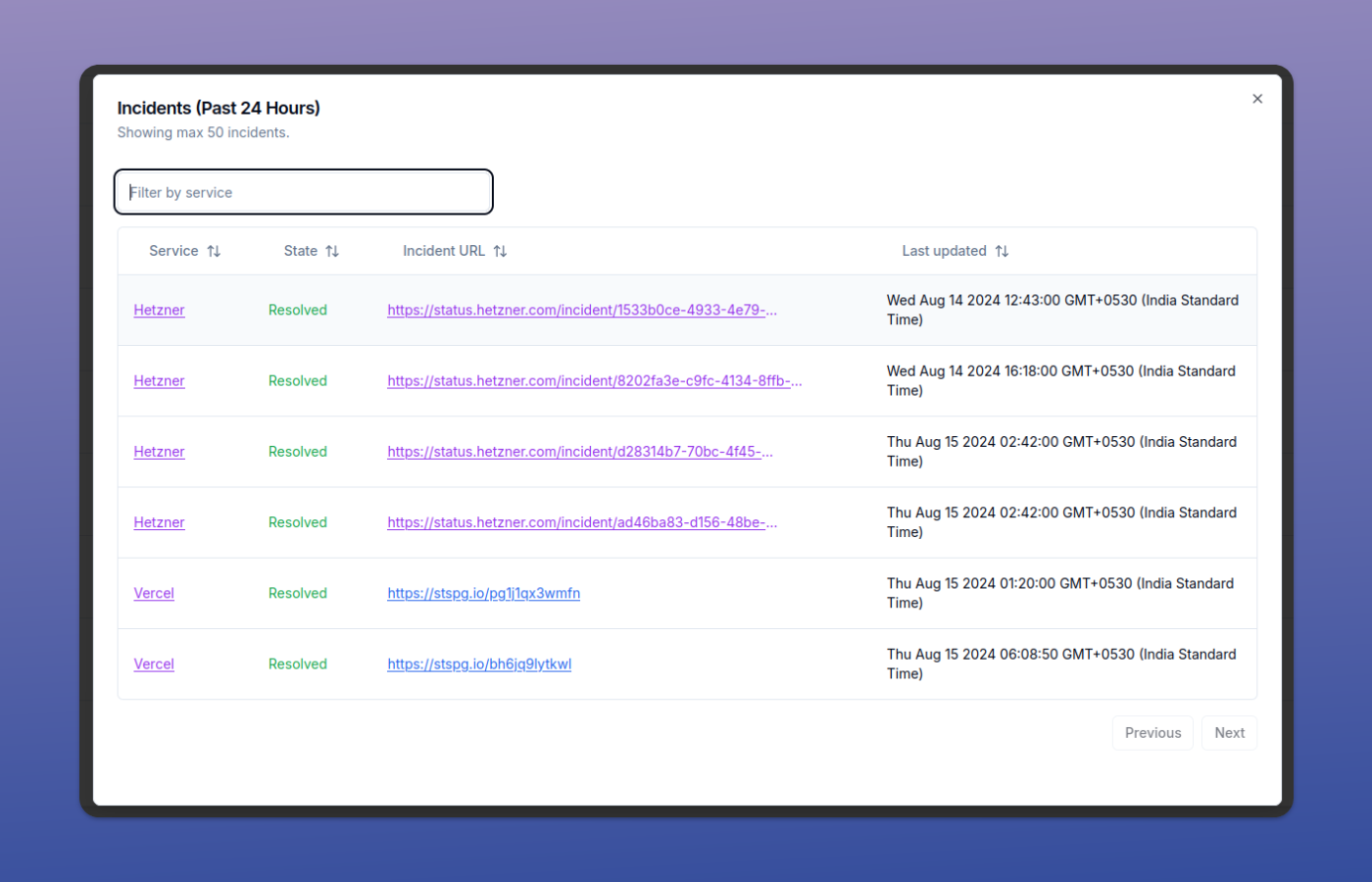
A recent question in an SRE forum triggered this train of thought.
How do I deal with alerts that are triggered by internal patching/release activities but don't actually cause a downtime? If we react to these alerts we might not have time to react to actual alerts that are affecting customers.
I've paraphrased the question to reflect its essence. There is plenty to unravel here.
My first reaction to this question was that the SRE who posted this is in a difficult place with systemic issues.
Systemic Issues
Without knowing more about the org and their alerting policies, let's look at what we can dig out based on this question alone