Major Cloud Outages of 2025

Cloud Outages and Their Impact
Cloud outages in 2025 ranged from minor ones affecting some sections of users, to major ones affecting hundreds or thousands of users. Services like Cloudflare and AWS on which many other services depend experienced outages that affected many due to the cascading effect.
Let's look at some of the major cloud outages in 2025.

- Cloud Outages and Their Impact
- Major Cloud Outages in 2025
- Microsoft Azure - 8 January
- Slack - 26 February
- PagerDuty - 26 February
- OpenAI - 8 April
- Zoom - April 16
- Google Cloud Platform - 12 June
- Microsoft Azure - 6 September
- Google Workspace - 18 September
- Amazon Web Services - October 20
- Microsoft Azure - 29 October
- Cloudflare - November 18
- OpenAI 26 November
- Cloudflare - December 5
- The Impact of Infrastructure Provider Outages
- Using A State Page Aggregator to Monitor Cloud Outages
- Conclusion
Major Cloud Outages in 2025
Microsoft Azure - 8 January
A networking configuration change in East US2 caused "connectivity issues, prolonged timeouts, connection drops, and resource allocation failures" across multiple Azure services. Loss of indexing data in the Azure PubSub service - which is used by the networking control plane to communicate between control entities and agents on individual hosts - caused networking configuration to not be delivered to the agents. The outage lasted around 50 hours.
It's noteworthy that the RCA report mentions that "Services that were configured to be zonally redundant and leveraging VNet integration may have experienced impact across multiple zones." The RCA also mentions a step to prevent this in future outages.
Link to incident: https://azure.status.microsoft/status/history/?trackingId=PLP3-1W8
Slack - 26 February
An outage in the Slack Events API caused custom applications, integrations, and bots to not work as expected. This outage was traced to the mitigation steps taken to resolve an earlier incident. This lasted around 25 hours.
Link to incident: https://slack-status.com/2025-02/d41e4bfd1ccae26a
PagerDuty - 26 February
Slack integration for PagerDuty was affected due to an outage in Slack (see above). Users who depend on PagerDuty applications for Slack were unable to receive notifications. With Slack becoming more and more popular as a central tool in incident management, this outage disrupted the workflow for many teams, including those who did not use the PagerDuty application.
This is a classic example of an incident notification tool itself being affected by an incident - in this case, on a dependent provider. PagerDuty notes in its future improvement points that it will work on "Improving our monitoring to ensure that we can respond faster to issues with our integration partners" and also to figure out other ways of improving the user experience in such cases.
Link to incident: https://status.pagerduty.com/posts/details/PB5WBMB
OpenAI - 8 April
OpenAI ran into capacity issues while handling requests for Sora, its sophisticated video generation model. To mitigate the problem, OpenAI rolled out Sora capabilities in the same order that users signed up for it. The issue was officially marked as resolved on 30th April - around 22 days after it was reported.
Link to incident: https://status.openai.com/incidents/01JRB888M6TJVDDKGCA1YZ3ZHT
Zoom - April 16
This started as a domain resolution failure when the zoom.us domain was blocked by its registrar. The TLD nameservers stopped resolving the domain as well as all its subdomains. This outage officially lasted around 1 hour 47 minutes, and received a lot of publicity due to Zoom's widespread usage.
Link to incident: https://www.zoomstatus.com/incidents/pw9r9vnq5rvk
Google Cloud Platform - 12 June
Affecting mainly Google Cloud services and a handful of Google Workspace services, this outage was caused by a bad automated update to Google Cloud's quota check system. The update propagated globally, affecting external API requests and impacting many products.
The incident lasted around 3 hours. 76 different Google Cloud services were affected.
Link to incident: https://status.cloud.google.com/incidents/ow5i3PPK96RduMcb1SsW
Microsoft Azure - 6 September
Multiple undersea cable cuts in the Red Sea caused widespread disruption to global communications passing through Azure's network.
As a workaround, Microsoft Azure rerouted traffic through alternate paths.
Link to Hacker News discussion: https://news.ycombinator.com/item?id=45152773
Google Workspace - 18 September
A resource contention issue in Google's authentication system caused login failures across many Google services. It was mitigated by increasing the available capacity.
The outage lasted 1 hour 13 minutes. Due to the key nature of the affected service (authentication), users were unable to access other services, increasing the blast radius of the outage.
Link to incident: https://www.google.com/appsstatus/dashboard/incidents/5V5yK8N8heBKnmdqS1eW
Amazon Web Services - October 20
A race condition in Amazon's DynamoDB's DNS caused prolonged impact in other AWS services in us-east-1. Many AWS services depend on DynamoDB internally. 141 services in AWS were affected by the outage.
Link to post-incident write up: https://aws.amazon.com/message/101925/
Another interesting video on this https://www.youtube.com/watch?v=YZUNNzLDWb8
Microsoft Azure - 29 October
A series of customer configuration changes resulted in incompatible metadata being generated in Azure's Content Delivery Network. "This configuration (with the incompatible metadata) completed propagation to a majority of edge sites by 15:39 UTC.", according to the report. Although their internal config protection system caught the impact when it became visible, and stopped all new and inflight configuration change requests, the bad configuration was already processed by the edge server.
Link to incident: https://azure.status.microsoft/status/history/?trackingId=YKYN-BWZ
A video retrospective: https://www.youtube.com/watch?v=PHvIYrWkAJU
Cloudflare - November 18
Cloudflare's network experienced an outage starting at around 11:20 UTC. Since this affected Cloudflare's Sites and Services, it resulted in thousands of websites being rendered inaccessible, thus multiplying the impact. A database permission change caused a larger than expected file to be fed into Cloudflare's Bot Management System, causing it to crash. This change was propagated all over the world, repeating the pattern we have seen in other outages where one bad change is replicated across the global network.
Link to incident: https://www.cloudflarestatus.com/incidents/8gmgl950y3h7
Analysis: https://blog.cloudflare.com/18-november-2025-outage/
OpenAI 26 November
Both OpenAI APIs and ChatGPT were affected by control plane failures in some of OpenAI's GPU clusters. The failure was caused by a global change to Kuberenetes namespace labels.
Link to incident: https://status.openai.com/incidents/3pn6gclf1cjx
Cloudflare - December 5
Cloudflare's dashboard and related APIs were affected by a change that was deployed to mitigate a React Server Components vulnerability.
Link to incident: https://www.cloudflarestatus.com/incidents/lfrm31y6sw9q
A detailed write up: https://blog.cloudflare.com/5-december-2025-outage/
The Impact of Infrastructure Provider Outages
In the second half of 2025, 3 outages caused major disruption, demonstrating once again that the lower the service in the stack, the larger the blast radius of the outage. Cloudflare (twice), Azure, and Amazon Web Services affected thousands of downstream cloud and SaaS services and customers.
An infrastructure outage can affect other services like dev tools and authentication providers. An authentication provider outage can affect other services like a remote monitoring tool in turn.
This is also reflected in the rise in outages in September, October, and November, when we saw Azure, AWS, and Cloudflare go down.
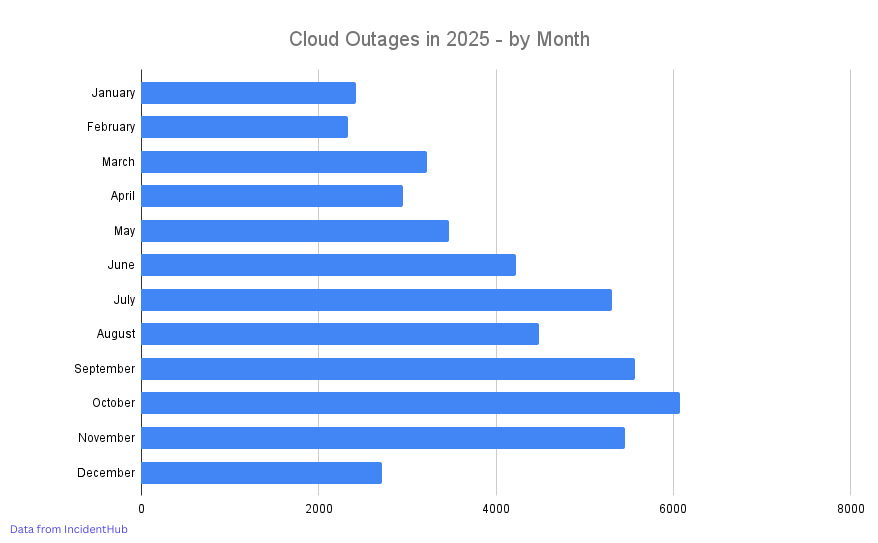
Data source: IncidentHub's monitoring of public status pages.
Overall, cloud provider outages remain the second highest category of outages in 2025, after cybersecurity providers.
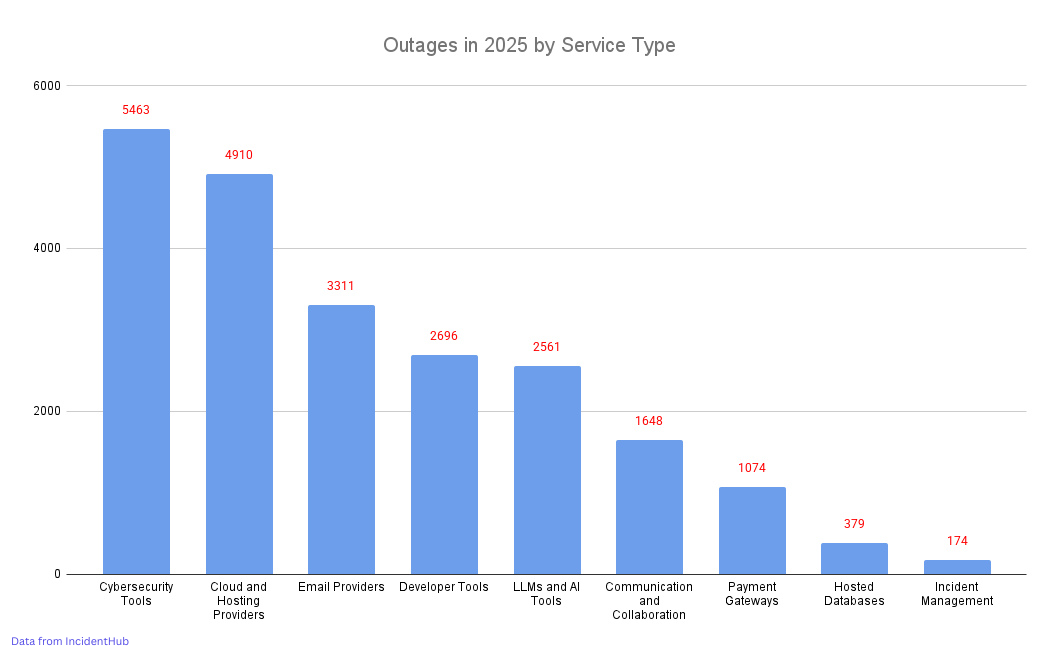
Data source: IncidentHub's monitoring of public status pages.
There is also another pattern in infrastructure provider outages. Such services use their own internal distributed infrastructure to propagate changes globally to control plane software like agents in other regions. A bad change will propagate with the same speed as a good one:
From the GCP June 12th report
"Given the global nature of quota management, this metadata was replicated globally within seconds."
Thus, the impact of such bad changes is not local and spreads quickly.
Each outage remains an opportunity to to improve processes. Most large cloud providers are proactive in sharing detailed technical root causes of outages.
Last but not the least, an outage is an extremely stressful experience for the folks on-call, especially when there are thousands of other services and users affected. Mitigating an outage in a complex, globally distributed system is a Herculean task.
Using A State Page Aggregator to Monitor Cloud Outages
IncidentHub is a cloud-based status page aggregator service that monitors the availability of your third-party cloud services. Outage detection is automatic and happens in real-time. In 2025 IncidentHub tracked more than 48000 outages across hundreds of SaaS and Cloud services.
Conclusion
2025 saw a number of major cloud outages, especially in the infrastructure layer, demonstrating the impact that a few providers can have on other services and users.
IncidentHub is not affiliated with any of the services and vendors mentioned in this article. All logos and company names are trademarks or registered trademarks of their respective holders
This article was first published on the IncidentHub blog.
You might also like: