The Definitive AWS Outage Report 2025: Reliability Analytics and Cascade Impact

Introduction
Amazon Web Services remains one of the most popular cloud providers, with 200+ services in 39 regions across the world. Like all providers, they have their share of outages.
In 2025, IncidentHub detected 38 AWS outages, of which the one on October 20th had the most widespread impact affecting hundreds of SaaS providers simultaneously. Payments were disrupted, students lost access to classrooms, developer tooling degraded, and some IT teams experienced alerting gaps.
In this post we look at the reliability of AWS in 2025 based on their own publicly available status page data aggregated by IncidentHub, with a deeper analysis of the cascading impact of the October 20th outage.

- Introduction
- Methodology
- Frequency of Outages
- Duration of Outages
- Outages by Service
- Is Reliability Improving, Staying the Same, or Getting Worse?
- Outage Dependency Mapping
- Regional Outage with Global Impact
- Surviving AWS Outages
- Conclusion
- FAQ
Methodology
We collected and analyzed the uptime of all AWS services and regions for a period of 1 year between 1st January 2025 and 31st December 2025. In this period, IncidentHub - status page aggregator - detected 38 outages across AWS products and regions. To detect cascading outages, we filtered out incident reports from SaaS vendors who acknowledged the cause as AWS on their status pages.
For this report, an "outage" is defined as an incident listed on AWS's status page that impacts or disrupts at least one AWS service. Each AWS status page incident was counted as a single outage, regardless of the number of services or regions listed.
We analyzed only 2025 incident data here.
A brief note on how IncidentHub collects outage data
IncidentHub - a status page aggregator - monitors public status page periodically across hundreds of SaaS and Cloud vendors. It detects outages, maintenance events, and changes in services and regions automatically. The end result is an aggregated dashboard of vendors - a single status page for all third-party service status pages.
We wanted to keep the analysis relevant to practitioners - actual users who rely on AWS. We focused on these aspects:
- Frequency of outages
- Duration of outages
- Outages by Service and Region
- Is Reliability Improving, Staying the Same, or Getting Worse?
- Outage Dependency Mapping - Which other SaaS providers were affected?
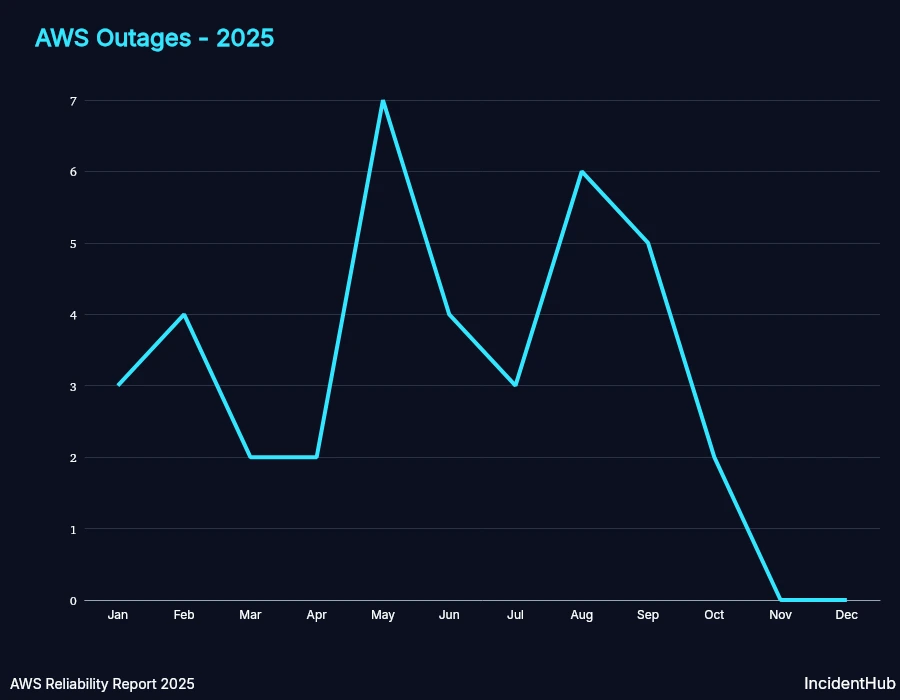
Frequency of Outages
AWS had at least one outage every month except for the last two in 2025. For a platform as large as AWS, this is not surprising. However, the real measure of reliability is the duration and the impact of the outages.
Duration of Outages
The shortest outage lasted around 14 minutes, whereas the longest was around 15 hours.
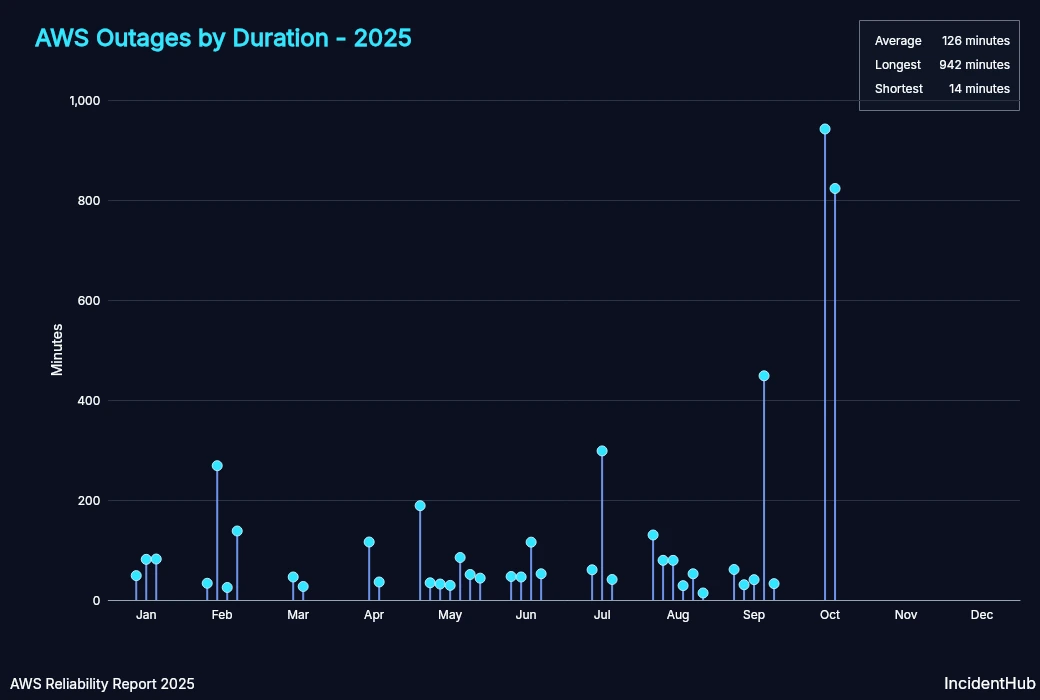
Average monthly MTTR was higher in Q3 than in Q1 and Q2. The October 20th outage being an outlier drove up the MTTR to be almost 12x that of January's in Q4.
| Month | MTTR (minutes) |
|---|---|
| Jan | 70.64 |
| Feb | 116.26 |
| Mar | 36.50 |
| Apr | 76.00 |
| May | 66.26 |
| Jun | 65.27 |
| Jul | 133.18 |
| Aug | 63.96 |
| Sep | 122.66 |
| Oct | 882.50 |
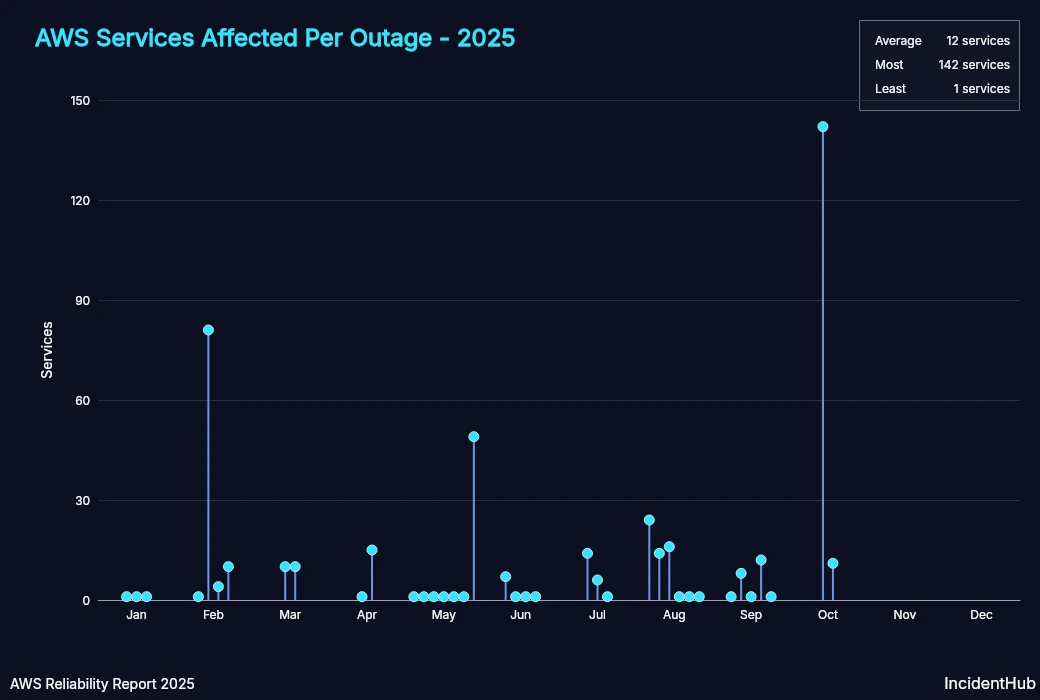
Outages by Service
There is usually no correlation between the number of affected services and the duration of the outage in most of the outages, except for the one on Feb 13th and on Oct 20th.
Services Affected per Outage
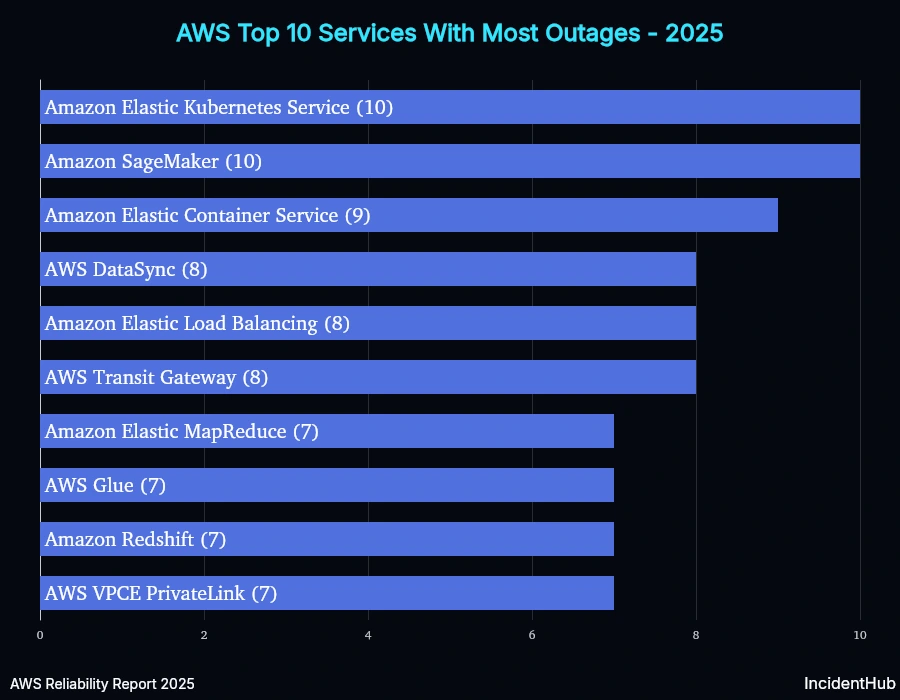
Services Which had the Highest Number of Outages
Regions with the Highest Number of Outages
The AWS us-east-1 region recorded the highest number of outages in 2025. This has been variously attributed to it being the oldest, busiest region, as well as many control plane services being hosted there. E.g. the IAM service, Cloudfront, and Route 53's control planes are in us-east-1.
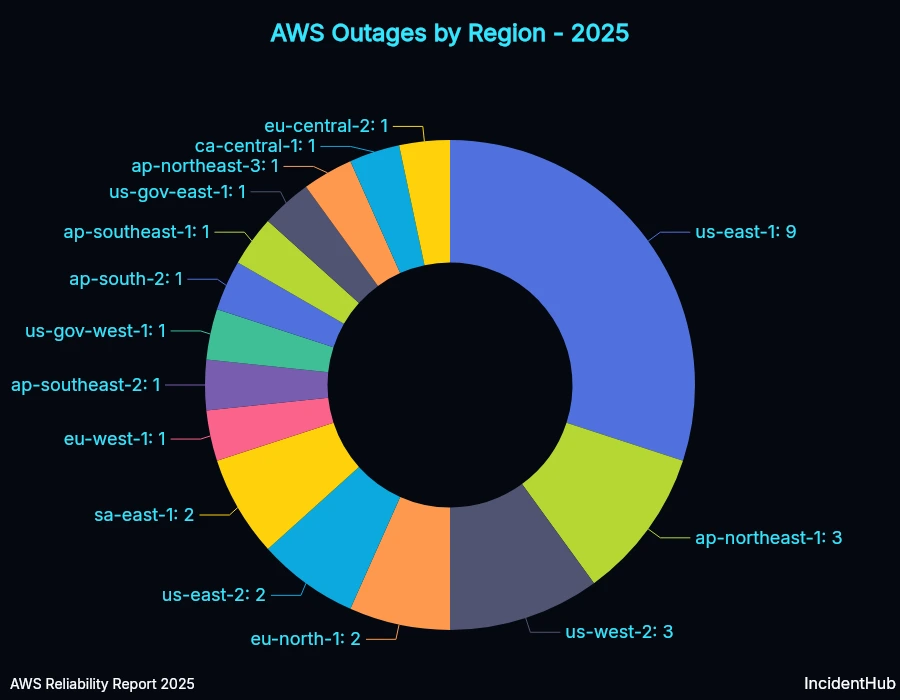
However, for the 20th October 2025 outage, the number of affected services in us-east-1 was high because a core service - DynamoDB - on which other AWS services depend, was affected in us-east-1 due to a race condition in its DNS management system as Amazon explains in their detailed summary. DynamoDB runs in other AWS regions too - so this outage could have theoretically happened in other regions as well. The AWS team rolled out the fix for the race condition to the first region by October 24th and by October 28th they had it across all regions worldwide.
Is Reliability Improving, Staying the Same, or Getting Worse?
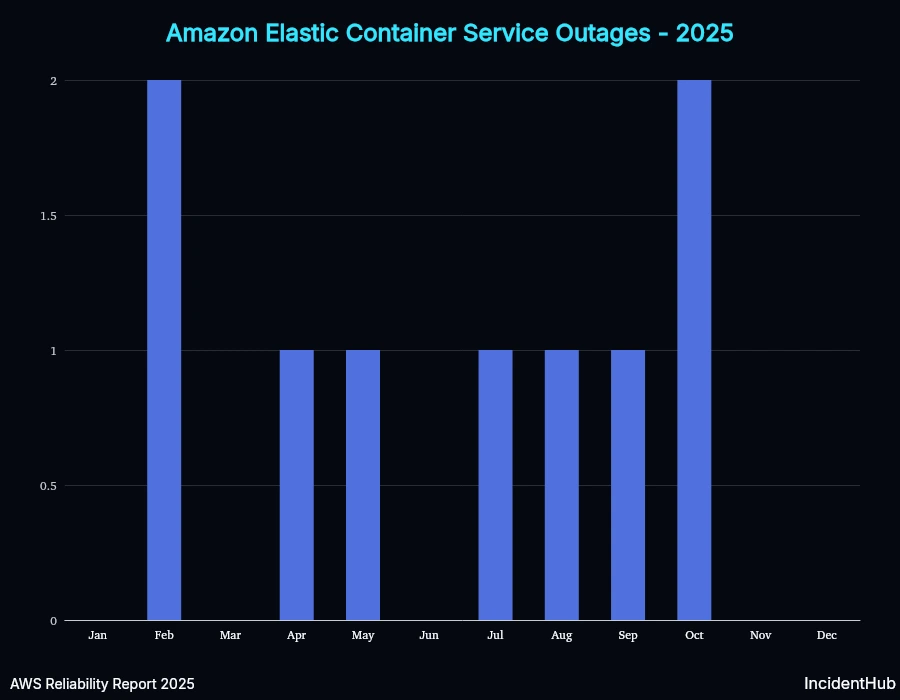
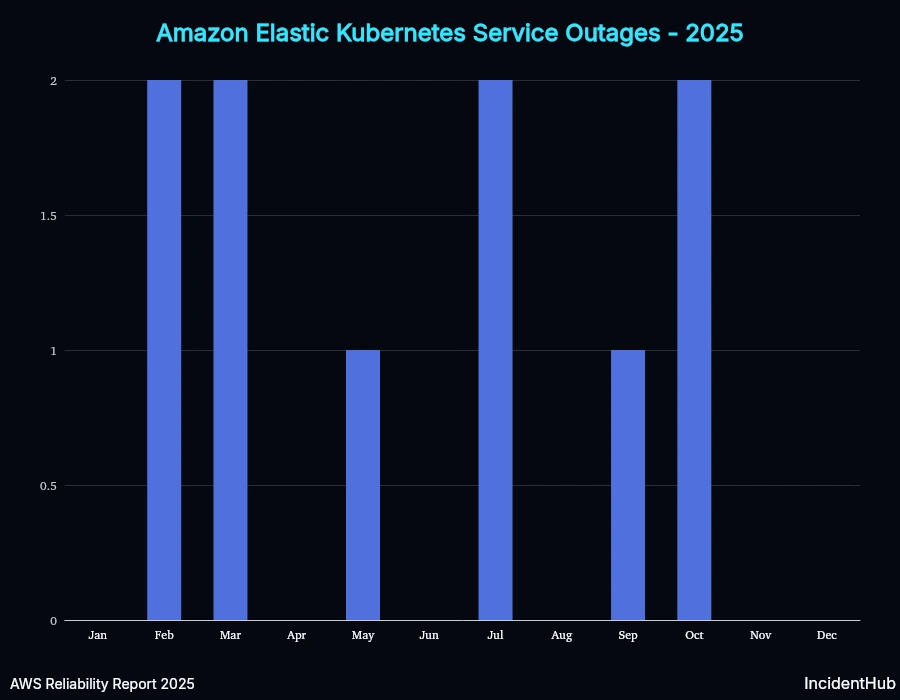
A quick look at service-wise outages for some of the top-10 services affected shows variable trends. However, overall for AWS as a whole, the average monthly outage duration increased in Q3 compared to Q1 and Q2, but the number of services affected decreased (except for the Oct 20th outlier).
EC2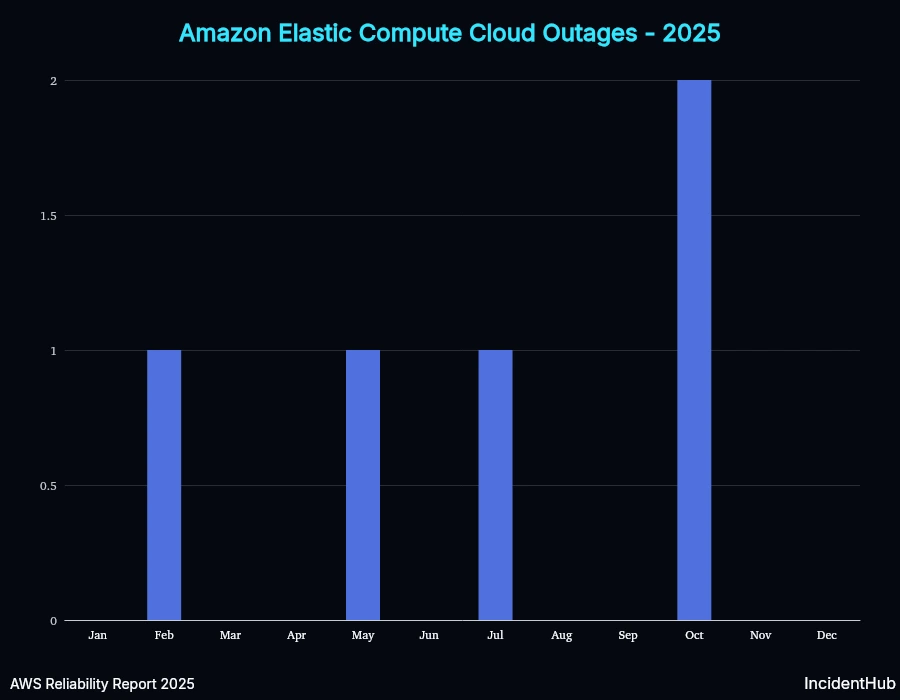
ECS
EKS
ELB
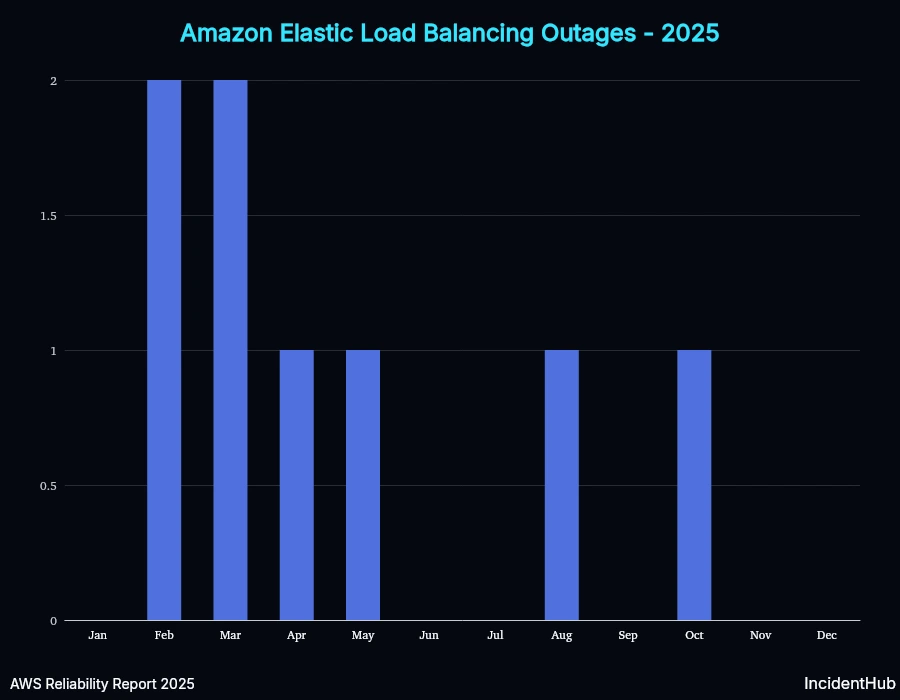
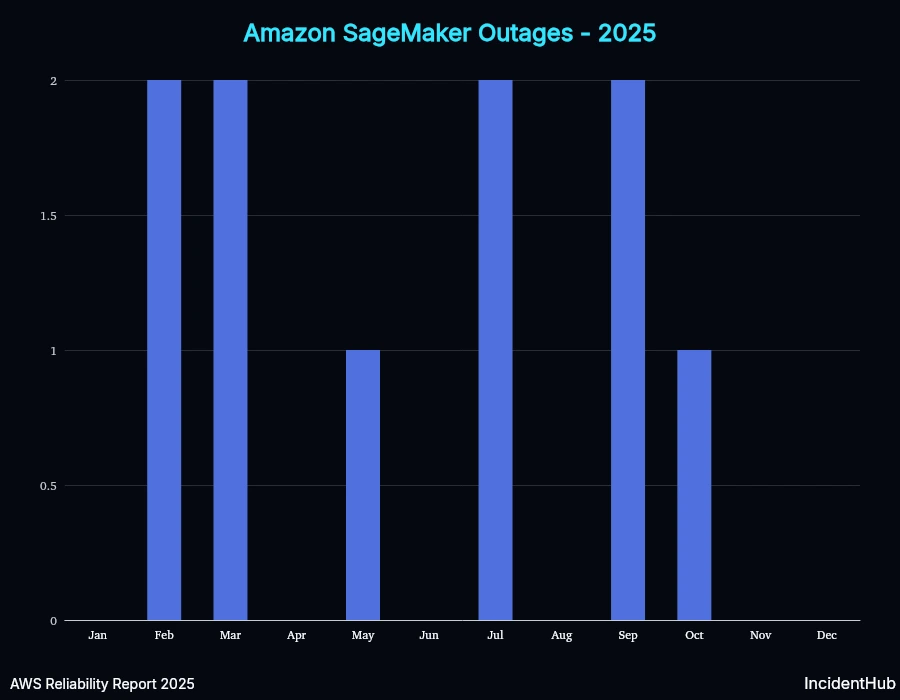
SageMaker
Outage Dependency Mapping
The AWS outage of Oct 20th was one of their biggest outages in 2025. In distributed systems, failures in one part of the system can result in cascading failures in other parts of the system. The same principle applies to SaaS providers and their dependencies. A lot of key AWS services were affected, and as a result, many SaaS providers. Since many SaaS providers use AWS directly and also other SaaS providers which in turn use AWS, the overall impact multiplied rapidly.
IncidentHub detected 400+ other SaaS outages in the same timespan as the AWS outage of the 20th - out of which 197 SaaS providers acknowledged the cause as AWS. The subsequent analysis takes only those 197 SaaS providers into account, although it's highly likely the blast radius was much larger.
While most SaaS providers either talked about how the AWS outage affected them, or did not mention AWS at all, Cloudflare explicitly mentioned that they were not affected by the AWS outage in any way. This is a good example of being upfront in user communication. Thousands of services depend on Cloudflare and these kind of declarations make it easier to debug issues.
Source: Cloudflare status page.
Note: The numbers are smaller than what somebody would expect the expected blast radius to be because:
- There are services that IncidentHub does not monitor yet.
- Not all affected services monitored by IncidentHub acknowledged the cause as AWS.
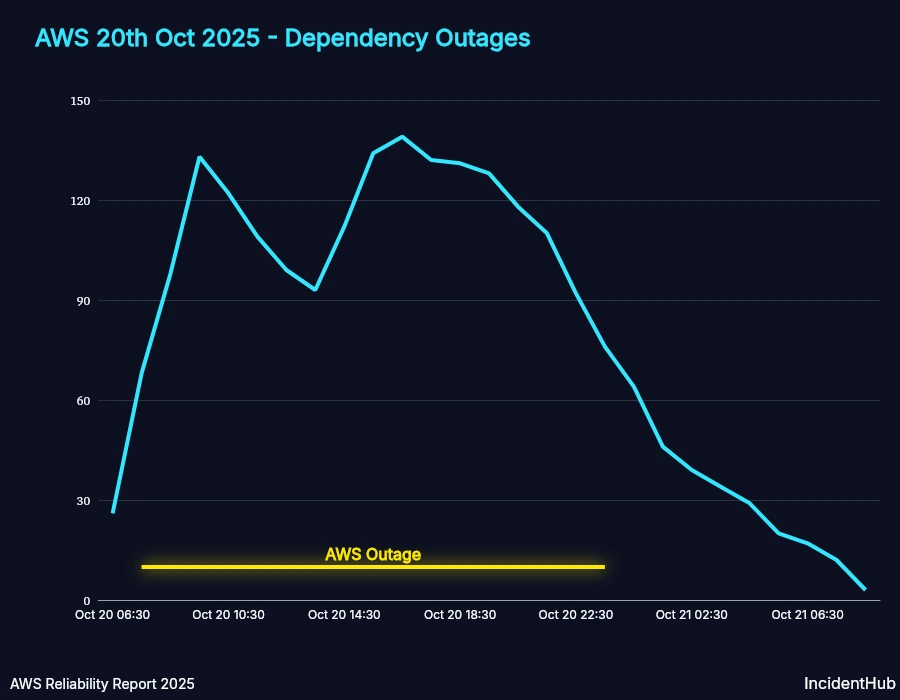
Cascading Outages Timeline
The graph below shows the number of outages in SaaS providers over time who acknowledged the cause as AWS. After AWS resolved the issue, it took time for some services to recover - this is expected due to their validating recovery measures and their reliance on direct or indirect dependencies which were themselves recovering.
Dependency Outages by SaaS Type
The top SaaS categories affected included Cybersecurity tools, Developer tooling, Communication and Collaboration tools, Education Technology Platforms, and CRM, Marketing, and Customer Support.
Notably, Observability and Incident Management tools also appear in the distribution - the very tools that teams rely on to detect outages.

Let's look at some of these categories in more detail.
Observability and Incident Management Providers
Observability data ingestion was affected in DataDog, Dynatrace and New Relic. As a result, monitoring systems in SaaS that use such data for alerting and incident management were affected.
Incident Management software were also affected - some directly, some indirectly. Efforts to move to another AWS region were made in some cases but it took hours. On call notifications were delayed or not sent at all.
| SaaS | Impact | Duration |
|---|---|---|
| StatusHub | SMS delivery issues | 22 hours and 49 minutes |
| PagerDuty | Delayed Notifications in US Region | 6 hours and 24 minutes |
| Opsgenie | Atlassian Cloud Services impacted | 15 hours and 58 minutes |
| Incident.io | Escalation delays | 7 hours and 0 minutes |
| Better Stack | Delayed email notifications due to AWS outage | 1 hour and 58 minutes |
| BugSnag | AWS outage impacting Smartbear ID logins and email notifications | 48 minutes |
| Grafana Cloud | Grafana K6: Some Test Runs May Not Start Due to AWS Outage | 4 hours and 51 minutes |
| Honeycomb | Delays in SLO, Service Maps processing | 25 hours and 24 minutes |
| DataDog Integrations | Several Web Integrations affected due to Vendors' outage in US1-east | 33 hours and 51 minutes |
| Dynatrace | Accessibility and login issues with Dynatrace UI | 8 hours and 29 minutes |
| New Relic | Cloud and Synthetics Data Ingest | 12 hours and 53 minutes |
| Axiom | System issues | 3 hours and 36 minutes |
| Sumo Logic | Problem with Tracing Collection, Authentication, Billing and Account Management, CSE Processing Pipeline and CSE APIs | 14 hours and 30 minutes |
Essentially, during the outage, visibility into your systems was impaired if you were dependent on SRE/Ops tools that use AWS in some way.
Developer tools
Developer tooling took a significant hit, with several platforms reporting outages well in excess of 20 hours - disrupting CI/CD pipelines, code review, and feature flag management simultaneously.
Outages in artifact repositories and container registries affected downstream services like managed Kubernetes platforms that depend on them.
| SaaS | Impact | Duration |
|---|---|---|
| GitHub | Copilot | 2 hours 30 minutes |
| GitLab | Package Registry | ~1 hour |
| Quay Container Registry | Writes disabled | 14 hours and 55 minutes |
| Docker Hub | Multiple services affected | ~4 hours |
| GitBook | Public content loading | 22 hours 15 minutes |
| Postman | Increased error rates | ~15 hours |
| LaunchDarkly | Elevated Latencies and Delays | 26 hours and 35 minutes |
| Bitbucket (and other Atlassian services) | Delays and missing notifications | 23 hours and 42 minutes |
| CircleCI | Job and pipeline failures, UI and API errors | 15 hours and 5 minutes |
| Codefresh | Build retries | 9 hours and 37 minutes |
| SonarQube Cloud | Endpoint request failures | 3 hours and 11 minutes |
| Cursor IDE | Service degradation | 12 hours and 51 minutes |
Infrastructure and Hosting Providers
Core infra services like some DNS providers were affected - leading to DNS propagation delays. Other cloud providers who depend on SaaS that use AWS saw impact on some of their services.
Hosting platforms Netlify and Render were down for 13+ hours, affecting websites running on them. DigitalOcean reported that their managed Kubernetes platform was affected due to Docker Hub issues, which were due to AWS, for 19+ hours.
| SaaS | Impact | Duration |
|---|---|---|
| Hostinger | Payment Processing Service Disruption | 11 hours and 30 minutes |
| WPEngine | Chat & Phone Support | 4 hours and 30 minutes |
| Railway | Deployments using Dockerhub are currently failing | 2 hours and 34 minutes |
| EngineYard | Slowness, timeouts, or trouble accessing some parts of platform and services | 11 hours and 32 minutes |
| Render | New database creation, backups, support tools | 13 hours and 18 minutes |
| Netlify | UI actions, outgoing emails from Netlify, builds, functions | 15 hours and 58 minutes |
| DigitalOcean | Multiple Services Disruption | 19 hours and 20 minutes |
| Fly.io | Deployment failures | 1 hour and 11 minutes |
| Shockbyte | [Shockbyte Panel] Email Provider Outage | 2 hours and 43 minutes |
IT Operations and MSP Tools
IT Ops and MSP tools were significantly affected, with several tools managing remote devices and endpoints remaining down for over 13 hours.
| SaaS | Impact | Duration |
|---|---|---|
| NinjaOne | Multiple third party providers continue to be impacted by cloud service outage - including SMS messaging | 8 hours and 4 minutes |
| Commvault Cloud (Metallic) | Service Interruption | 13 hours and 23 minutes |
| Jamf | Jamf: US-East-1 Disruption | 11 hours and 55 minutes |
| Spiceworks | Cloud Help Desk outage | 7 minutes |
| Kaseya | Datto RMM - Concord, Vidal - Service Disruption (error messages, agent disconnections) | 13 hours and 1 minute |
| Auvik Networks | Partial service degradation | 1 hour and 6 minutes |
| Halo | Email processing and scheduled actions | 3 hours and 28 minutes |
Education Technology Platforms
More than 13 education technology platforms reported outages, some lasting well over a day.
| SaaS | Impact | Duration |
|---|---|---|
| PowerSchool | Multiple PowerSchool Products - Users are unable to access application | 27 hours and 33 minutes |
| Blackboard by Anthology | Learn SaaS - US-EAST-1 Region - Multiple Sites Inaccessible | 17 hours and 33 minutes |
| Turnitin | Turnitin Service Incident - 20th October 2025 | 21 hours and 46 minutes |
| Imagine Learning | Multiple Products - Some Assessments and Activities Not Scoring Correctly | 7 hours and 25 minutes |
| Renaissance | Renaissance programs | 22 hours and 28 minutes |
| HMH | Intermittent Service Degradation | 23 hours and 37 minutes |
| Remind | Issues with accessing or using Remind web & mobile apps | 6 hours and 12 minutes |
| Instructure | Some users may encounter errors when accessing Canvas | 17 hours and 57 minutes |
| Clever | Users unable to login to Clever | 35 hours and 52 minutes |
| Great Minds | Content/Assessment interactives, SSO failures, Platform latency | 19 hours and 43 minutes |
| Savvas Learning Company | Savvas Realize Performance Issues | 11 hours and 55 minutes |
| Pearson | Pearson Online Classroom: Degraded Performance | 7 hours and 10 minutes |
| Ellucian Cloud | Services degraded | 14 hours and 38 minutes |
Payments
Outages in payments providers mean lost revenue, and there were plenty of them.
| SaaS | Impact | Duration |
|---|---|---|
| Kraken Digital Asset Exchange | US Dollar (USD) Deposits via Plaid Unavailable | 3 hours and 44 minutes |
| Bluefin | Phone System Outage | 8 hours and 15 minutes |
| Coinbase Commerce | Site Performance - Login, Trading, Transactions | 17 hours and 25 minutes |
| Coinbase Prime | Site Performance - Login, Trading, Transactions | 17 hours and 25 minutes |
| Paddle | Issue affecting Checkouts and Order Processing | 4 hours and 53 minutes |
| Tebex | Payment Decline Errors | 4 hours and 28 minutes |
Although there were services which acknowledged that they managed to failover to another region, the lag in recovery across many SaaS vendors suggests that region-level failover is not straightforward in practice.
Regional Outage with Global Impact
Was this a regional AWS failure that also took down global services? Yes, in some cases, by extension. The AWS failure itself remained regional.
This happened due to second and third, and more, order effects:
System Issues
The scope of impact is increasing as more IAM credentials expire and are unable to refresh, leading to additional service disruptions. Additionally authenticating to our EU console isn't working, as our SAML partner is experiencing issues.
From the Axiom status page.
Dashboard access and support request submission issues in multiple regions
We are currently investigating an issue with dashboards loading and customer support in multiple regions.
From the Qualtrics status page.
We are affected by AWS outage in us-east-1
We are currently investigating intermittent failures when creating new services in us-east-1 region. If you already have a running service, connections should continue to work as expected.
https://console.cloud.timescale.com/ is operational, although we’ve received some reports of certain assets not loading properly.
This issue appears to be related to an ongoing AWS service outage, which is also being reported on the AWS Service Health Dashboard.
At this time, we are not aware of any further impact. We’ll provide an update as soon as more information becomes available. 2 Affected Services:
- Regions / US East (N. Virginia) / us-east-1
- Global Services / Console & APIs
From the TigerCloud status page.
Outage Chains
It's not straightforward to map a complete dependency graph of all the services that were affected by this outage, but we did manage to uncover some interesting aspects.
Here are 3 chains we uncovered, each showing how a vendor's outage was not triggered by AWS directly, but by another vendor's outage that depended on AWS - illustrated by incidents at StatusHub and Railway.
AWS -> Twilio -> StatusHub
Twilio We are currently investigating elevated latency and timeout errors for Twilio Rest API, impacting the Multiple Twilio services. Our engineering team is actively working on the issue, and we will provide another update in 60 minutes or as soon as more information becomes available.
StatusHub Due to major outage affecting our SMS partner, SMS delivery is currently affected and messages may not be delivered.
AWS -> Docker Hub -> Railway
Docker Hub Docker is continuing to experience service disruption as a result of issues with an upstream service provider. We are actively working to remediate where possible.
Railway Builds and deploys are taking longer than usual as Dockerhub recovers after their recent outage.
Upstream dependencies cannot be avoided. Even with a multi-cloud approach - which itself is not straightforward and may not be feasible architecturally or financially for everyone - key dependencies can remain tied to single providers.
Surviving AWS Outages
Reconsider if us-east-1 is necessary for your workloads
The us-east-1 region is the oldest and busiest in AWS, and it saw the highest number of outages in 2025. Even though the biggest one in 2025 could have occurred in any region, us-east-1 still leads in the total number of outages. You have no control over the control plane and global services that run there, so you can avoid us-east-1 if your workloads can run in other regions.
Audit your own dependency chain
First level dependencies for AWS are easy to find. Second and further level ones are not so easy. However, listing down all your dependencies is a great first step.
Monitor third-party dependencies, not just AWS directly
Tools like status page aggregators can monitor third-party dependencies seamlessly, without the need to manually check each and every status page or account for any differences in their structure or notifications. Monitoring the specific components you use (e.g. EC2 in AWS) is necessary to keep your alerts relevant.
Accept that multi-cloud is not a silver bullet
Multi-cloud sounds like an attractive proposition until you realize that:
- It may not be feasible for your organization either architecturally or financially.
- Your other SaaS dependencies may not be multi-cloud and thus won't be as resilient.
The first step is knowing when your dependencies are down.
Conclusion
2025 showed us that an infrastructure provider outage can cascade across hundreds of dependent services and that was true for AWS too. 38 outages were recorded across 200+ products and 39 regions. Most AWS outages in 2025 remained confined to a single region. The October 20th outage led to many downstream SaaS providers experiencing outages too.
Layers of downstream dependencies amplify a single provider's outage. Monitoring your SaaS dependencies is more crucial than ever to stay ahead of the impact such outages can have on your business.
FAQ
How many AWS outages were there in 2025?
In 2025, IncidentHub detected 38 outages across AWS services and regions.
What caused the AWS outage on October 20th 2025?
The AWS outage on October 20th 2025 was attributed by AWS to a failure in DynamoDB's automatic DNS management system.
What is the highest MTTR for AWS outages in 2025?
The highest MTTR for AWS outages in 2025 was 882.50 minutes.
Which AWS services were affected by the AWS outage on October 20th 2025?
The AWS outage on October 20th 2025 affected more than 140 AWS services.
Is us-east-1 really less reliable than other AWS regions?
us-east-1 recorded the most outages in 2025. This may be influenced by its age and service density, even though the biggest one in 2025 could have occurred in any region. You have no control over the control plane and global services that run there, you can avoid us-east-1 if your workloads can run in other regions.
How long did the AWS October 2025 outage last?
The AWS October 2025 outage lasted around 15 hours.
Does multi-cloud actually protect against AWS outages?
Not necessarily. Your other SaaS dependencies may not be multi-cloud and thus won't be as resilient.
How can I monitor AWS outages and their impact on my SaaS tools?
A status page aggregator like IncidentHub can help you monitor AWS outages and their impact on your SaaS tools seamlessly, without the need to manually check each and every status page. You only need to monitor the specific components (in AWS and other SaaS) and IncidentHub can take care of that too.
Sign up for an IncidentHub account and stay on top of all your SaaS dependencies
Photo by Scott Rodgerson on Unsplash
IncidentHub is not affiliated with any of the services and vendors mentioned in this article. All logos and company names are trademarks or registered trademarks of their respective holders. Amazon Web Services and AWS are trademarks of Amazon.com, Inc. This report is independent and not affiliated with or endorsed by Amazon.
This article was first published on the IncidentHub blog.