GitHub Outages 2025 - 2026: Reliability Analysis and Outage History

Executive Summary
Hashicorp's co-founder Mitchell Hashimoto decided to pull out his Ghostty project from GitHub in April 2026 due to GitHub's reliability issues. He did this after 18 years of using GitHub, saying that GitHub "is no longer a place for serious work".
GitHub has experienced a significant decline in reliability over the past 6 months, and Hashimoto is not alone in expressing this sentiment. In the past 12 months, GitHub has experienced 48 major outages, including outages in GitHub Actions, Copilot, Pull Requests, and core Git operations.
This article analyzes in depth GitHub's outage history between May 2025 and April 2026, the possible causes, and the impact on developers and businesses. IncidentHub has monitored every GitHub outage for the past 12 months and beyond - read on to find out what the data reveals.

- Executive Summary
- GitHub by the Numbers: May 2025 - April 2026
- Impact of Outages on Developers and Businesses
- Where GitHub Fails Most: Service-by-Service Analysis
- What is Behind the Outages?
- When GitHub Fails: Patterns in the Data
- How GitHub Compares: GitLab & Bitbucket Reliability
- The Real Cost of GitHub Outages
- Conclusion: GitHub's Reliability Crisis
- FAQ
GitHub by the Numbers: May 2025 - April 2026
Total Incidents: 257 incidents tracked, out of which 48 were major outages. February 2026 was the worst month in this period with 37 incidents, with Feb and Apr 2026 being the worst in terms of major incidents (7 each).
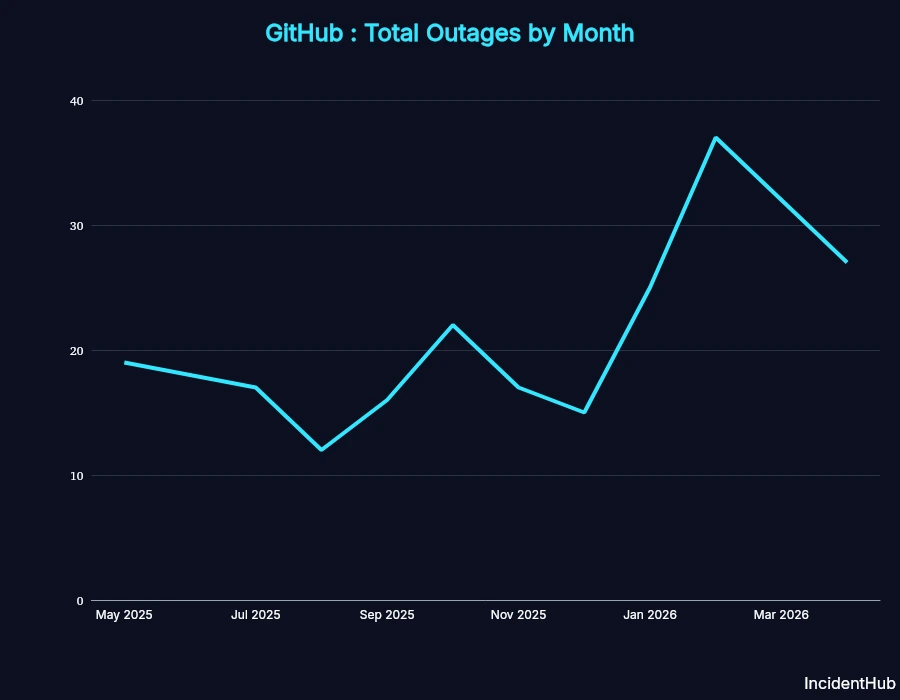
Total Downtime for Major Outages: 112 hr 18 min
A major outage is defined as one that leads to significant disruption to the service, affecting a large number of users or businesses.
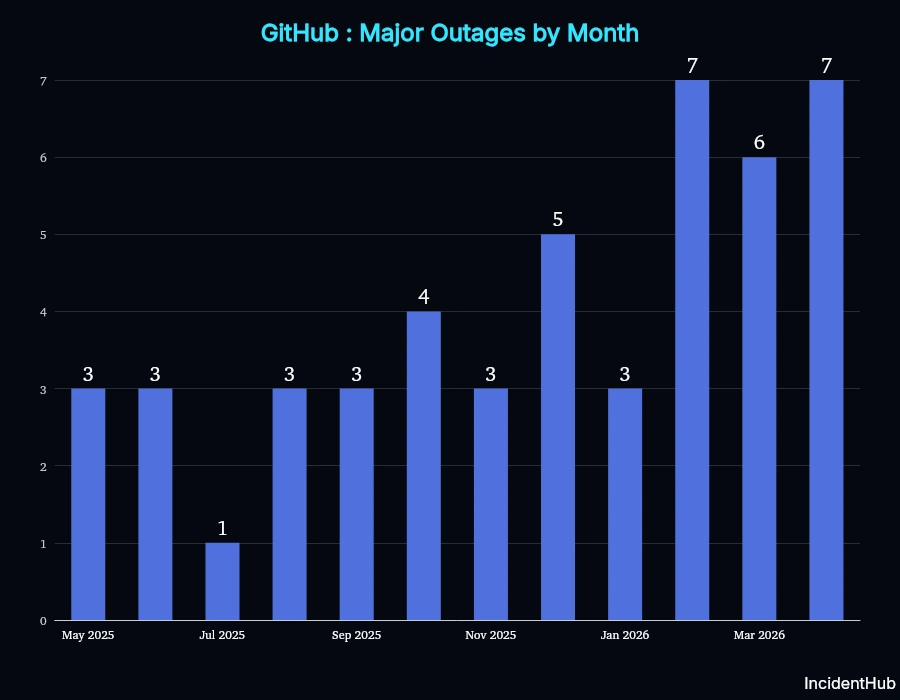
The frequency of major outages has been increasing since December 2025.
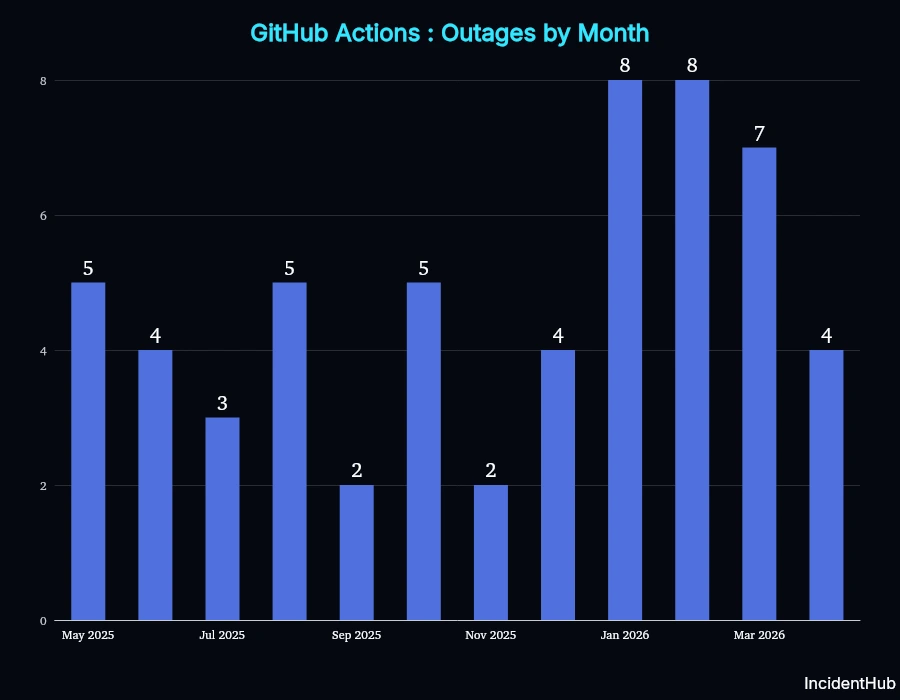
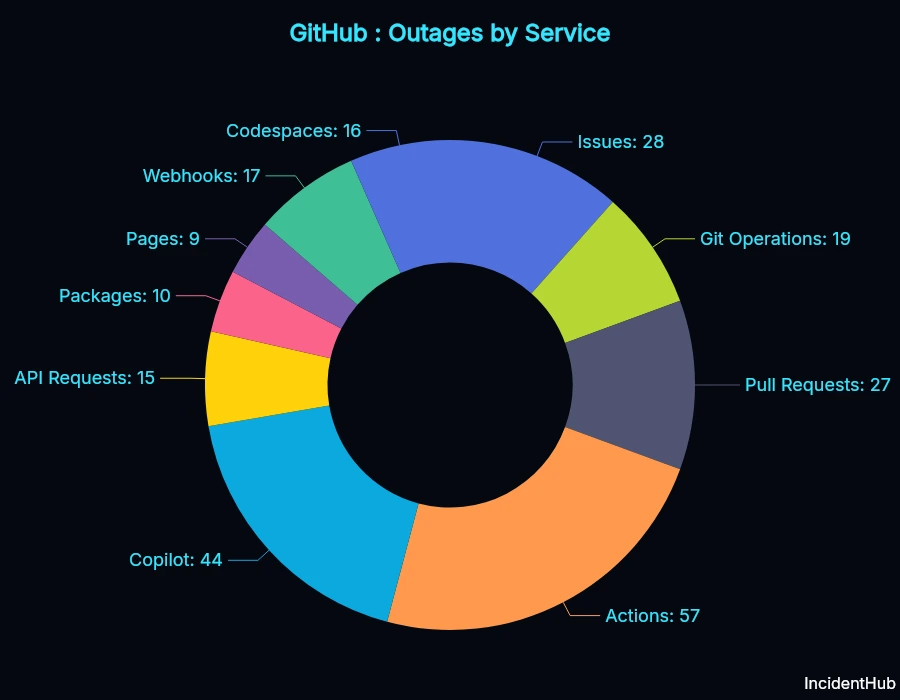
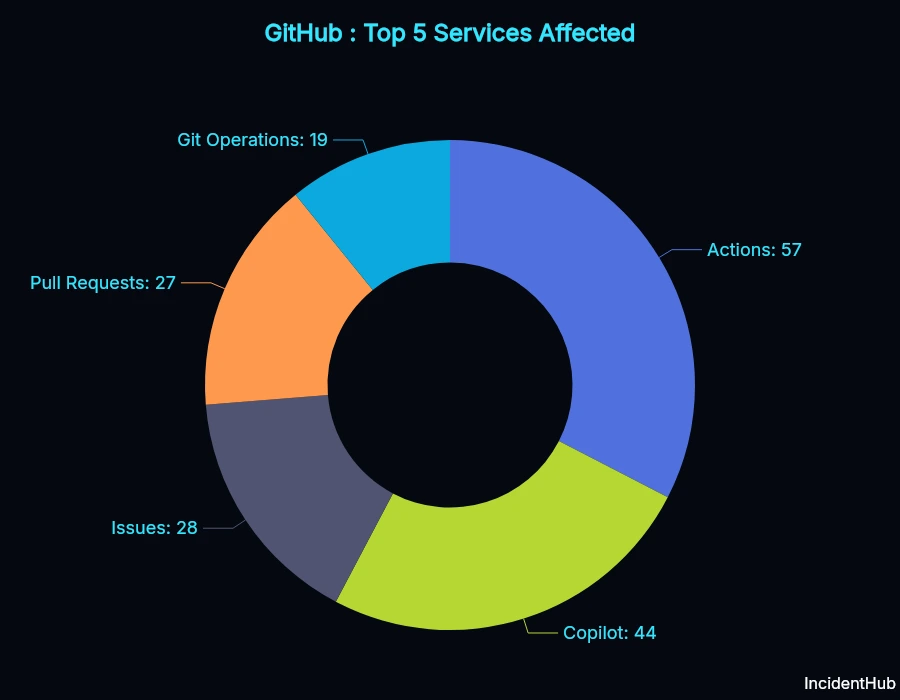
Most Affected Service: GitHub Actions (57 outages)
GitHub Actions was the most affected service, with 57 outages between May 2025 and April 2026.
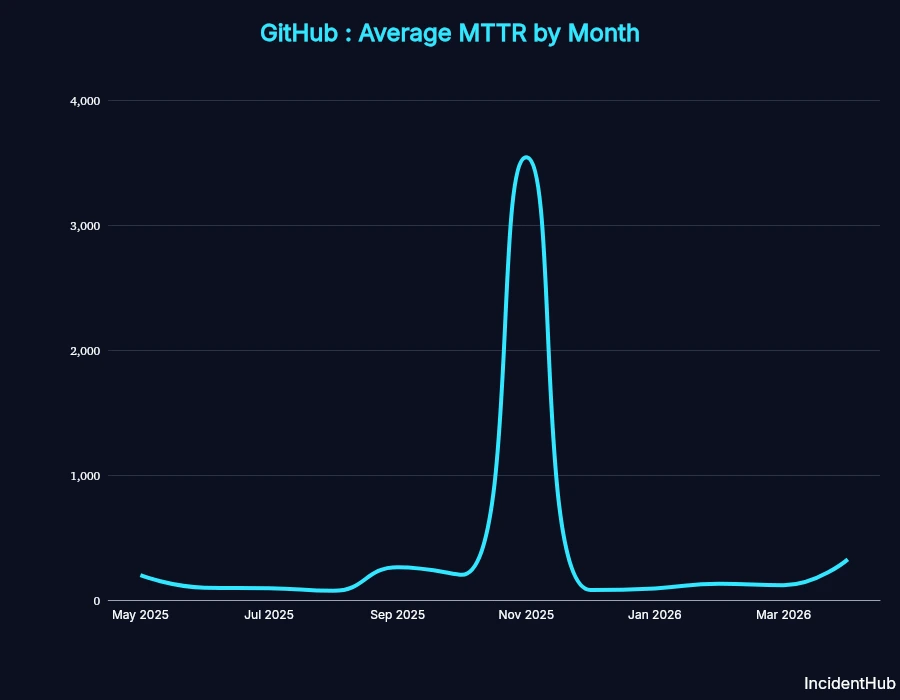
Average MTTR: 6 hr 7 min
Key Findings
- GitHub Actions had 3x more incidents than core Git operations
- Copilot experienced 44 outages affecting AI coding workflows
- Pull Requests had 27 outages, including data corruption
Impact of Outages on Developers and Businesses
The Ghostty Decision (April 2026)
Mitchell Hashimoto, co-founder of Hashicorp, announced on his personal blog that his project Ghostty will be moving out of GitHub. Hashimoto wrote that GitHub "is no longer a place for serious work" and that they have been planning to move out of GitHub for a while. The announcement comes just after the Apr 27th outage (although the timing is coincidental) - which lasted around 2 hours and 13 minutes and affected the Copilot Cloud Agent.
Ghostty is a terminal emulator that is built with Zig and has over 52k stars on GitHub.
Zig Programming Language (November 2025)
In November 2025, the maintainenrs of the Zig programming language decided to move their project away from GitHub to Codeberg (a nonprofit alternative).
Zig's maintainers cited serious bugs with Actions and issues with the overall engineering culture of GitHub as some of the drivers behind the decision.
Where GitHub Fails Most: Service-by-Service Analysis
GitHub Actions Outages
IncidentHub tracked 57 incidents between May 2025 and April 2026 for GitHub Actions. GitHub Actions also had the lion's share of major incidents (16) in the same period.
The worst impacted months were Jan and Feb 2026, with 8 outages each.
Significant Actions Outage Timeline
1st October 2025 : GitHub Actions runners on MacOS encountered a 46% error rate due to capacity constraints. The outage lasted for more than 10 hours, caused by a "permission failure" which was in turn triggered by a scheduled event.
23rd October 2025 : GitHub Actions failed to cater to all requests with 1.4% of overall workflow runs and 29% of larger runner jobs failing. The underlying cause for the customer facing impact was partially identified as a database performance degradation. Time taken to restore service: 3 hours 26 minutes.
29th October 2025 : Multiple GitHub services experienced degraded performance due to a third-party provider outage. Lasting for around 9 hours, this outage affected Codespace, Actions, Enterprise Importer, and Copilot Metrics. 0.5% of workflow runs and 9.8% of larger hosted runner jobs in GitHub Actions failed during this period. The post-mortem report acknowleges that the team will reduce critical path dependencies on the third-party provider, which was identifed as Microsoft Azure in one of the status updates.
2nd February 2026 : GitHub Actions experienced degraded performance due to an issue with their compute provider - which is Azure. Time taken to restore service: 3 hours and 40 minutes. This was an outage with widespread impact affecting Copilot Coding Agent, Copilot Code Review, CodeQL, Dependabot, GitHub Enterprise Importer, and Pages also.
27th April 2026 : GitHub Actions experienced degraded performance due to an issue with their Elasticsearch cluster. The outage lasted for around 6 hours and 16 minutes. The outage affected Pull Requests, Actions, Issues, and Packages. The incident updates mention "This is due to an ongoing infrastructure issue that we have been investigating." but does not provide any more details.
Root cause from GitHub's post-mortems:
- Capacity constraints
- Underlying provider dependencies (Microsoft Azure)
- Database overload
- Bad configuration changes rollout
GitHub Copilot Outages
GitHub had 44 Copilot-specific outages in the period, with 9 major incidents. Copilot had 10 outages in Feb 2026 alone.
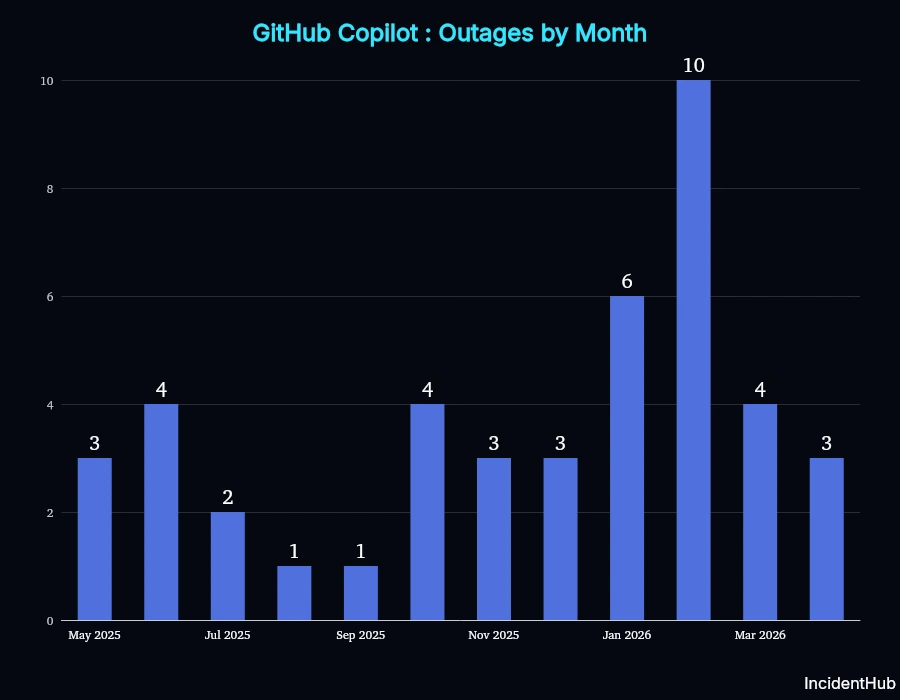
Notable Copilot Outage Timeline:
1st October 2025 : Gemini 2.5 Pro users experienced errors when using large context requests in Copilot. This lasted for more than 45 hours.
5th November 2025 : Copilot Code Completions was partially unavailable for around 2 hours. The outage affected around 0.9% users who saw errors while using code completion.
5th November 2025 : Another Copilot Code Completions outage, this was related to the previous outage on the same date.
9th February 2026 : This issue with Copilot Policy Propagation Delays took almost a week (6+ days) before it was pronounced resolved. The root cause was identified as a code change that led to an increase in the number of background jobs, which caused a bottleneck in the shared worker queue.
Core Git Operations Outages
19 incidents affected Git push/pull/clone in the period, with incidents peaking in Feb 2026 with 5 outages.
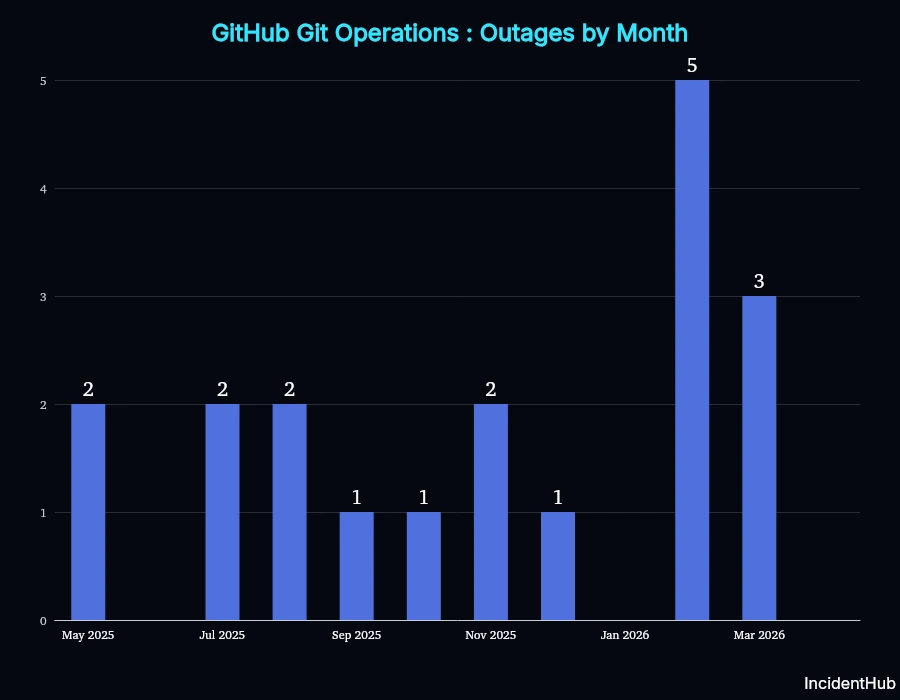
A seemingly simple yet one causing major disruption incident was the one that lasted for around 47 hours between Oct 22 and Oct 24 2025. Any git operations via ssh ended up either taking a long time to complete or failing altogether. The root cause was identified as resource exhaustion on backend servers. This brings up the question of whether such key infrastructure is monitored sufficiently, and why it took so long to mitigate the issue.
A pattern seen in some of the outages affecting Git operations was being unable to handle higher load than expected, or not planning for higher load. This was seen here and, here. Some issues were due to external factors like fiber cuts.
Pull Requests Outages: The Data Corruption Incident
Pull Requests saw a total of 27 outages in the period, with the most severe bug being the Merge Queue regression on April 23, 2026. For merge groups containing more than one PR and using the squash merge strategy, changes from previously merged PRs were reverted, effectively leaving the codebase in a corrupted state. GitHub's report said that 2092 pull requests were affected. Significantly, this outage was identified by customer reports and support cases.
According to GitHub's report, this was caused by an incomplete feature flag and inadequate test coverage.
Other Service Outages
- GitHub Issues: 28
- API Requests: 15
- Packages: 10
- Pages: 9
- Webhooks: 17
- Codespaces: 16
What is Behind the Outages?
GitHub's downtime is the result of multiple factors, the primary ones being the following.
AI-Driven Traffic Explosion
2024: There was a 59% surge in the number of contributions to generative AI projects, with total projects being 518 million, according to the Octoverse 2024 report.
2025: Developers made 1 billion commits (+25.1% YoY), with 230 new repositories being created every minute. The 2025 Octoverse report also notes that "Generative AI is now standard in development".
Code pushes were 82.19 million on average per month in 2025 compared to 65 million in 2024.
The Octoverse is GitHub's annual report that tracks activity and growth across GitHub's user base and analyzes trends.
In an article on the GitHub blog, GitHub's CTO, Vlad Fedorov, stated that GitHub was not ready to handle the surge in traffic caused by AI coding tools:
"We started executing our plan to increase GitHub’s capacity by 10X in October 2025 with a goal of substantially improving reliability and failover. By February 2026, it was clear that we needed to design for a future that requires 30X today’s scale. The main driver is a rapid change in how software is being built. Since the second half of December 2025, agentic development workflows have accelerated sharply."
While they planned for a 10x surge in traffic, the real need was closer to 30x. Although the quote says "since the second half of December 2025", indications of an increase in AI-coding related traffic were there earlier as stated in the Octoverse 2025 report.
And one of the biggest things in 2025? Agents are here. Early signals in our data are starting to show their impact, but ultimately point to one key thing: we're just getting started and we expect far greater activity in the months and years ahead.
The (Incomplete) Azure Migration
GitHub's core platform migration to Microsoft Azure started in October 2025 and is still ongoing. Some components had already been migrated earlier. According the CTO's note, the "demands of AI and Copilot" have led to capacity constraints in its Virginia data center, and the move to Azure is necessary to keep up with the demands.
Although the Azure migration is often stated as a cause, it is more about how much of the migration is not completed. The migration, in the GitHub's CTO's words, will be prioritized over feature development to ensure there is sufficient capacity to handle the surge in traffic by both vertical and horizontal scaling.
In Mar 2026, only 12.5% of GitHub traffic was served from Azure.
Architectural Issues
In GitHub's March 2026 official blog post, CTO Vlad Fedorov stated that the recent issues (in February and March 2026) were due to "rapid load growth, architectural coupling that allowed localized issues to cascade across critical services, and inability of the system to adequately shed load from misbehaving clients."
Root cause analyses of both the Feb 2nd and March 5th outages revealed single points of failure.
When GitHub Fails: Patterns in the Data
Analyzing GitHub's downtime data reveals some interesting facts.
Severity Distribution (major vs minor)
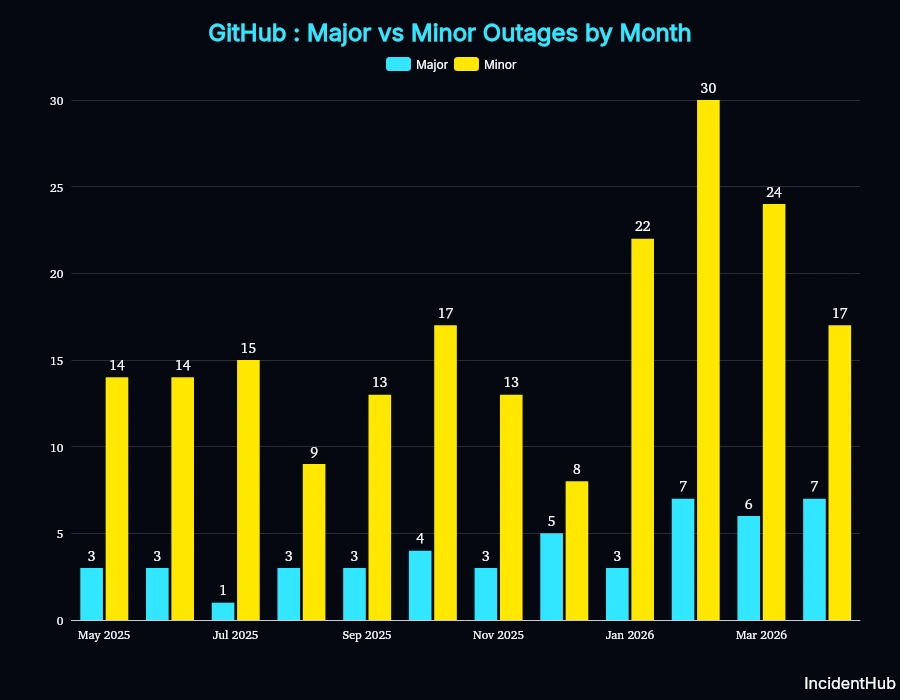
As you can see from the graph, the number of both major and minor outages has been increasing since December 2025.
Root Causes of GitHub Outages
Pinpointing a single root cause in a distributed system outage is not always possible. We analyzed GitHub's outages from GitHub's own incident reports and categorized them by the primary stated root cause in the period of May 2025 to April 2026.
| Root Cause | Outage Count |
|---|---|
| Capacity | 83 |
| Deployment | 71 |
| External Dependencies | 31 |
| Configuration | 30 |
| Internal | 24 |
| Uncategorized | 11 |
| Infrastructure/Network | 7 |
Capacity Issues
A lot of GitHub's availability issues were due to load and capacity problems, accounting for 83 of the 257 outages. There are indications that capacity in many services did not automatically scale up to handle the load. Manual scaling up was required.
Examples:
On April 1, 2026, between 07:29 and 12:41 UTC, some customers experienced elevated 5xx errors and increased latency when using GitHub Copilot features that rely on /agents/sessions endpoints (including creating or viewing agent sessions). The issue was caused by resource exhaustion in one of the Copilot backend services handling these requests, in turn, causing timeouts and failed requests. We mitigated the incident by increasing the service’s available compute resources and tuning its runtime concurrency settings. Service health returned to normal and the incident was fully resolved by 12:41 UTC.
On May 20, 2025, between 12:09 PM UTC and 4:07 PM UTC, the GitHub Copilot service experienced degraded availability, specifically for the Claude Sonnet 3.7 model. During this period, the success rate for Claude Sonnet 3.7 requests was highly variable, down to approximately 94% during the most severe spikes. Other models remained available and working as expected throughout the incident.
The issue was caused by capacity constraints in our model processing infrastructure that affected our ability to handle the large volume of Claude Sonnet 3.7 requests.
We mitigated the incident by rebalancing traffic across our infrastructure, adjusting rate limits, and working with our infrastructure teams to resolve the underlying capacity issues. We are working to improve our infrastructure redundancy and implementing more robust monitoring to reduce detection and mitigation time for similar incidents in the future.
Capacity issues also caused cascading effects:
On February 17, 2026, between 17:07 UTC and 19:06 UTC, some customers experienced intermittent authentication failures affecting GitHub Actions, parts of Git operations, and other authentication-dependent requests. On average, the Actions error rate was approximately 0.6% of affected API requests. Git operations ssh read error rate was approximately 0.29%, while ssh write and http operations were not impacted. During the incident, a subset of requests failed due to token verification lookups intermittently failing, leading to 401 errors and degraded reliability for impacted workflows.
The issue was caused by elevated replication lag in the token verification database cluster. In the days leading up to the incident, the token store’s write volume grew enough to exceed the cluster’s available capacity. Under peak load, older replica hosts were unable to keep up, replica lag increased, and some token lookups became inconsistent, resulting in intermittent authentication failures.
We mitigated the incident by adjusting the database replica topology to route reads away from lagging replicas and by adding/bringing additional replica capacity online. Service health improved progressively after the change, with GitHub Actions recovering by ~19:00 UTC and the incident resolved at 19:06 UTC.
We are working to prevent recurrence by improving the resilience and scalability of our underlying token verification data stores to better handle continued growth.
This was the same incident declared in https://www.githubstatus.com/incidents/xs6xtcv196g7
Configuration Issues
Bad configuration changes triggered many of the incidents. In distributed systems, such changes can have a cascading effect on other components as we saw in 2025's Cloudflare and GCP outages. Examples:
On February 12, 2026, between 00:51 UTC and 09:35 UTC, users attempting to create or resume Codespaces experienced elevated failure rates across Europe, Asia and Australia, peaking at a 90% failure rate.
The disconnects were triggered by a bad configuration rollout in a core networking dependency, which led to internal resource provisioning failures. We are working to improve our alerting thresholds to catch issues before they impact customers and strengthening rollout safeguards to prevent similar incidents.
On April 22, 2026, between 15:16 UTC and 19:18 UTC, users experienced errors when interacting with Copilot Chat on github.com and Copilot Cloud Agent. During this time, users were unable to use Copilot Chat or Copilot Cloud Agent. Copilot Memory (in preview) was not available to Copilot agent sessions during this time. The issue was caused by an infrastructure configuration change that resulted in connectivity issues with our databases. The team identified the cause and restored connectivity to the database. Copilot Chat and Cloud Agent for github.com were restored by 18:16 UTC. Remaining regional deployments were restored incrementally, with full resolution at 19:18 UTC. We have taken steps to prevent similar infrastructure changes from causing these kinds of database operations in the future.
Infrastructure/Network Issues
Network/Infrastructure issues are not always in GitHub's control, e.g. fiber cuts, power outages, etc.
On July 23rd, 2025, from approximately 14:30 to 16:30 UTC, GitHub Actions experienced delayed job starts for workflows in private repos using Ubuntu-24 standard hosted runners. This was due to resource provisioning failures in one of our datacenter regions. During this period, approximately 2% of Ubuntu-24 hosted runner jobs on private repos were delayed. Other hosted runners, self-hosted runners, and public repo workflows were unaffected.
To mitigate the issue, additional worker capacity was added from a different datacenter region at 15:35 UTC and further increased at 16:00 UTC. By 16:30 UTC, job queues were healthy and service was operating normally. Since the incident, we have deployed changes to improve how regional health is accounted for when allocating new runners, and we are investigating further improvements to our automated capacity scaling logic and manual overrides to prevent a recurrence.
On March 19, 2026 between 16:10 UTC and 00:05 UTC (March 20), Git operations (clone, fetch, push) from the US west coast experienced elevated latency and degraded throughput. Users reported clone speeds dropping from typical speeds to under 1 MiB/s in extreme cases. The root cause was network transport link saturation at our Seattle edge site, where a fiber cut affecting our backbone transport resulted in saturation and packet loss. We had a planned scale-up in progress for the site that was accelerated to resolve the backbone capacity pressure. We also brought online additional edge capacity in a cloud region and redirected some users there. Current scale with the upgraded network capacity is sufficient to prevent reoccurrence, as we upgraded from 800Gbps to 3.2Tbps total capacity on this path. We will continue to monitor network health and respond to any further issues.
This was the same incident declared in https://www.githubstatus.com/incidents/xs6xtcv196g7
Internal Issues
The "internal" category includes outages caused by application bugs, kernel issues, etc.
On July 21st, 2025, between 07:00 UTC and 09:45 UTC the API, Codespaces, Copilot, Issues, Package Registry, Pull Requests and Webhook services were degraded and experienced dropped requests and increased latency. At the peak of this incident (a 2 minute period around 07:00 UTC) error rates peaked at 11% and went down shortly after. Average web request load times rose to 1 second during this same time frame. After this period, traffic gradually recovered but error rate and latency remained slightly elevated until the end of the incident.
This incident was triggered by a kernel bug that caused a crash of some of our load balancers during a scheduled process after a kernel upgrade. In order to mitigate the incident, we halted the roll out of our upgrades, and rolled back the impacted instances. We are working to make sure the kernel version is fully removed from our fleet. As a precaution, we temporarily paused the scheduled process to prevent any unintended use in the affected kernel. We also tuned our alerting so we can more quickly detect and mitigate future instances where we experience a sudden drop in load-balancing capacity.
Other causes ranged from insufficient pre-deploy checks as well as internal certificates expiring, causing downstream failures:
From Nov 18, 2025 20:30 UTC to Nov 18, 2025 21:34 UTC we experienced failures on all Git operations, including both SSH and HTTP Git client interactions, as well as raw file access. These failures also impacted products that rely on Git operations.
The root cause was an expired TLS certificate used for internal service-to-service communication. We mitigated the incident by replacing the expired certificate and restarting impacted services. Once those services were restarted we saw a full recovery.
We have updated our alerting to cover the expired certificate and are performing an audit of other certificates in this area to ensure they also have the proper alerting and automation before expiration. In parallel, we are accelerating efforts to eliminate our remaining manually managed certificates, ensuring all service-to-service communication is fully automated and aligned with modern security practices.
GitHub's Plan to Mitigate Future Outages
These are based on the GitHub's public blog posts and post-mortem reports:
- Improve observability
- Improve automated detection
- Migrate more traffic to Azure
- Improve rollout safeguards
- Improve automatic mitigation
How GitHub Compares: GitLab & Bitbucket Reliability
Methodology
IncidentHub monitors GitHub, GitLab, and Bitbucket 24/7. Here's how they compare over the same 12-month period.
Incident Frequency
| Service | Incidents |
|---|---|
| GitHub | 257 |
| GitLab | 132 |
| Bitbucket | 27 |
GitHub had almost double the incidents as GitLab. However, these numbers do not take into account the number of projects hosted at GitLab or Bitbucket, and their traffic.
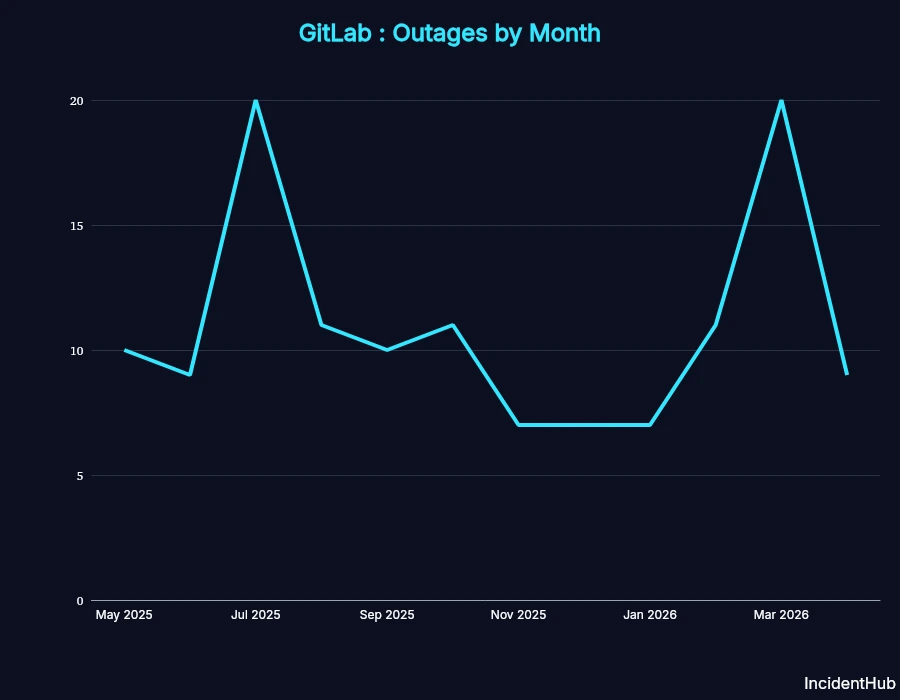
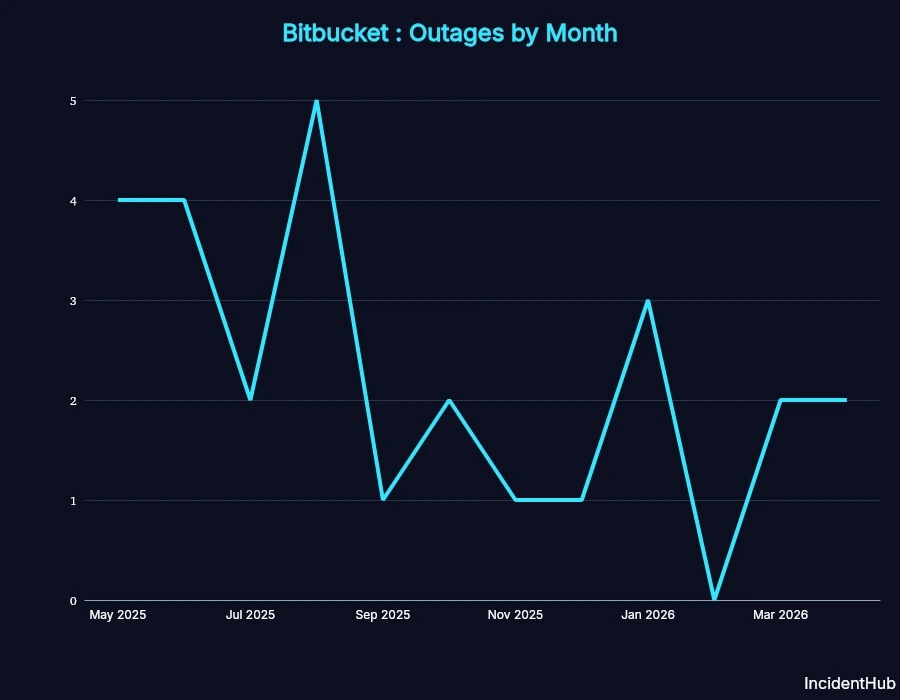
While no platform is perfect, GitHub's reliability has notably declined since December 2025.
The Real Cost of GitHub Outages
GitHub hosts over 630 million projects contributed by 180+ million developers. Many of these projects are extensively used by businesses and organizations.
A GitHub outage can impact far beyond just developer productivity.
Productivity Loss
- Unable to review Pull Requests
- Loss of productivity due to Copilot outages
- Blocked deployments and pipelines during Actions outages
- Lost work due to issues like the PR corruption incident
Business Impact
- CI/CD pipelines down = no production releases
- Enterprise customers paying for unreliable service
Trust Erosion
- Customers and businesses lose confidence after repeated outages in the same services
Conclusion: GitHub's Reliability Crisis
The data clearly indicates that GitHub's reliability has declined significantly. GitHub's leadership has acknowledged the issues, and promised to prioritize reliability over feature development. However, the challenges facing them are on multiple fronts - an ever-increasing AI-driven traffic explosion, a partial Azure migration which needs to be pushed towards completion to handle capacity, and architectural issues.
FAQ
How reliable is GitHub in 2026?
GitHub's reliability has declined significantly since December 2025. For its reliability to improve in 2026, they have to focus on the following on their stated goals - choosing to improve reliability over feature development, migrating more traffic to Azure, and improving rollout safeguards.
What caused GitHub's outages in the last 12 months?
The main causes of GitHub's outages in the last 12 months were capacity issues, deployment, and configuration issues.
Which GitHub service faced the most outages in the last 12 months?
GitHub Actions faced the most outages in the last 12 months, with 57 outages.
IncidentHub is not affiliated with any of the services and vendors mentioned in this article. All logos and company names are trademarks or registered trademarks of their respective holders. This report is independent and not affiliated with or endorsed by GitHub, GitLab, or Bitbucket.
This article was first published on the IncidentHub blog.